







怎么用java读取pdf中的表格
0

如题 。注:不要http://blog.csdn.net/bacoder/article/details/43536157这个地址上的答案。这个方法编译都通不过

最佳答案
0
编译不通过要看不通过的原因,这个工具应该是可以读取pdf里面表格的。
http://pdfbox.apache.org/download.cgi
收获园豆:100
不通过的原因我觉得是和jar包的版本有关。另外的话由于看不到底层封装的逻辑,我没办法进行底层了解。还有就是pdfbox这个jar主要处理的是文字和图像信息,针对于表格这块,貌似并不给力
其他回答(3)
0
0
ITEXT插件方法
/** * @param pdf PDF文件路径 * @param txt 输出文本文件路径 * @throws IOException */ public void parsePdf(String pdf, String txt) throws IOException { PdfReader reader = new PdfReader(pdf); PrintWriter out = new PrintWriter(new FileOutputStream(txt)); Rectangle rect = new Rectangle(70, 80, 490, 580); RenderFilter filter = new RegionTextRenderFilter(rect); TextExtractionStrategy strategy; for (int i = 1; i <= reader.getNumberOfPages(); i++) { strategy = new FilteredTextRenderListener(new LocationTextExtractionStrategy(), filter); out.println(PdfTextExtractor.getTextFromPage(reader, i, strategy)); } out.flush(); out.close(); reader.close(); }
PDFBOX插件方法
PDDocument document = PDDocument.load( args[0] ); if( document.isEncrypted() ) { document.decrypt( "" ); } PDFTextStripperByArea stripper = new PDFTextStripperByArea(); stripper.setSortByPosition( true ); Rectangle rect = new Rectangle( 10, 280, 275, 60 ); stripper.addRegion( "class1", rect ); List allPages = document.getDocumentCatalog().getAllPages(); PDPage firstPage = (PDPage)allPages.get( 0 ); stripper.extractRegions( firstPage ); System.out.println( "Text in the area:" + rect ); System.out.println( stripper.getTextForRegion( "class1" ) );
你的第二个pdfbox方法我试过。List allPages = document.getDocumentCatalog().getAllPages();
这句话编译通不过的。为什么获取的是一个List对象
@小白江红: 你可以确认下pdfbox的版本,可能新的包里把这个deprecated了,或者查下pdfbox的官方api
@CaiYongji: 我试过pdfbos最新的2.0.4和以前通用的1.8.4 好像都不行
@小白江红:
List allPages = (List) document.getDocumentCatalog().getPages();
@CaiYongji: 这样编译没问题了 可是运行的时候会报类型转换异常,说不能转换为list 类型
@小白江红: 刚刚手写,亲测通过。
import java.awt.Rectangle; import java.io.File; import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.pdmodel.PDPage; import org.apache.pdfbox.pdmodel.PDPageTree; import org.apache.pdfbox.text.PDFTextStripperByArea; /** * @author caiyongji * */ public class TestMain { public static void main(String[] args) throws Exception{ PDDocument document = PDDocument.load(new File("C:\\TEST\\RAND_TR649.1.pdf")); PDFTextStripperByArea stripper = new PDFTextStripperByArea(); stripper.setSortByPosition( true ); Rectangle rect = new Rectangle( 10, 280, 275, 60 ); stripper.addRegion( "class1", rect ); PDPageTree allPages = document.getDocumentCatalog().getPages(); PDPage firstPage = (PDPage)allPages.get( 0 ); stripper.extractRegions( firstPage ); System.out.println( "Text in the area:" + rect ); System.out.println( stripper.getTextForRegion( "class1" ) ); } }
@CaiYongji: 东西能出来吗?效果怎么样?还有就是你用的什么版本的jar包
@小白江红:
- 能出来,是Rectangle rect = new Rectangle( 10, 280, 275, 60 );这个区域里的所有文字。
- 2.0.4版本
- 下面是控制台信息,[]是文字区域,标红的是pdf内的内容
Text in the area:java.awt.Rectangle[x=10,y=280,width=275,height=60]
POPULATION AND AGING organization provi
PUBLIC SAFETY solutions that addre
SCIENCE AND TECHNOLOGY
and private sectors
@CaiYongji: 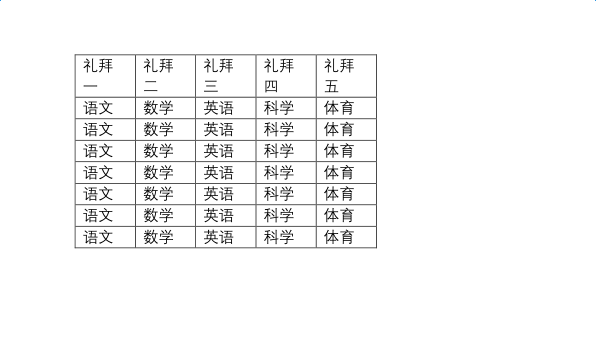

@小白江红: 恭喜!
@CaiYongji: 第一张是原始的PDF 第二张是效果图。你看第二行的一二三四五,它与上面的礼拜的位置发生了变化,无法一一对应。这个效果和PDF直接读取文本信息的效果是一样的
@小白江红: 理论上就是这样的结果。至于间距样式就不是pdfbox所关心的了,你需要把数据显示到其他地方。本身控制台就不存在样式。
@CaiYongji: 这样的效果我直接用PDFbox的文本读取方法就可以做到的。看来pdfbox还做不到那么人性化。谢谢你啊
@小白江红: 不客气。其实,我推荐你去看他的官方文档,对你更有帮助。
@CaiYongji: 我分给错人了 不好意思啊 手残党
@小白江红: 小事儿!
@小白江红: 你好,请问你是怎么处理的呀,我也用的pdfbox提取的表格中的内容,不过因为表格中的内容中有换行符,导致提取处理的内容错位,无法精确比对差异的地方是第几页第几行
@小白江红: 现在有个项目需要详细比对两个pdf文档内容是否相同,具体的差异有哪些,然后用pdfbox写到java代码,但是上面那个问题总是无法解决。我用的是pdfbox1.8 版本的,请问大神能提示下如何解决表格中有换行符导致的错位问题吗,这边急需。谢谢!
@CaiYongji: 我今天试了下,发现stripper中没有addRegion()的方法呀,请告知?
@小白江红: 如果PDF表格中有空格 读取到EXCel 怎么解决