






python 爬虫
-1



最佳答案
0
可以使用一些自动化测试工具 比如selenium webdriver边点击边获取信息。
收获园豆:50
关键是它的答案不固定,有填空的,有下拉菜单的,还有点击选择的。模拟登录搞不定。
查看源码里选项都有吧 可以用driver.getPageSource() 获取到所有数据
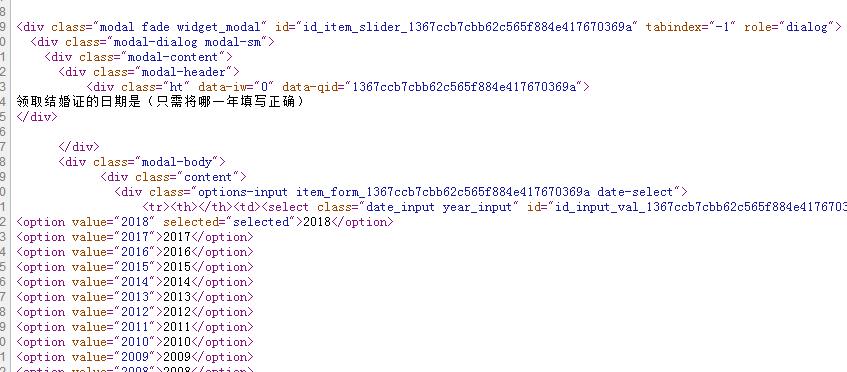
@ycyzharry: 这样只能拿到这一个答案方向的题,它是树状结构的,一道题如果有4个答案,那么就会对应4个不同的问题,这样还是拿不到整个问题和答案。这只是一个选择题,它里边还有填空题,我们怎么去模拟
其他回答(1)
0
异步加载,抓包
抓到包后,它每次data里的参数的个数不固定,
