






有关Java web爬虫问题
0
[已解决问题]
解决于 2020-03-25 20:29

源代码如下:
import java.util.Scanner;
import java.util.ArrayList;
public class WebCrawler
{
public static void main(String[] args)
{
ArrayList<String> listOfPendingURLs = new ArrayList<>();
ArrayList<String> listOfTraversedURLs = new ArrayList<>();
System.out.println("Enter a URL : ");
String URLString = new Scanner(System.in).nextLine();
try
{
listOfPendingURLs.add(URLString);
while(!listOfPendingURLs.isEmpty() && (listOfTraversedURLs.size() <= 100))
{
String urlString = listOfPendingURLs.get(0);
listOfPendingURLs.remove(listOfPendingURLs);
if(!listOfTraversedURLs.contains(urlString))
{
listOfTraversedURLs.add(urlString);
System.out.println("Crawling :" + urlString);
java.net.URL url = new java.net.URL(urlString);
Scanner input = new Scanner(url.openStream());
int current = 0;
while(input.hasNext())
{
String line = input.nextLine();
current = line.indexOf("http:",current);/**String类中的其中一种方法indexOf(s,fromIndex)
*返回字符串中fromIndex之后出现的第一个字符串s的下标。如果没有匹配的,返回-1。
*这里的意思是:返回URL
*/
while(current > 0)
{
int endIndex = line.indexOf("\"",current);//假设URL以“(引号)结束
if(endIndex > 0)
{
String newURL = new String();
newURL = line.substring(current,endIndex);
if(!listOfTraversedURLs.contains(newURL))
{
listOfPendingURLs.add(newURL);
}
else
current = -1;
}
}
}
}
}
}
catch(java.net.MalformedURLException ex)
{
System.out.println("Invalid URL");
}
catch(java.io.IOException ex)
{
System.out.println("I/O Errors: no such file");
}
}
}控制台结果显示:
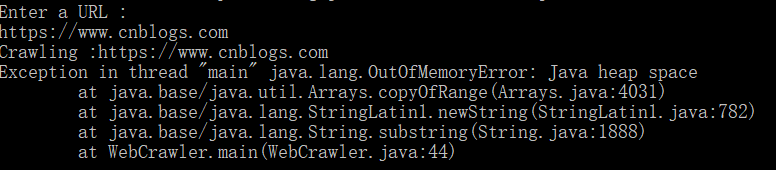
请问改报错怎么解决?为什么会出现该类错误?谢谢!


最佳答案
其他回答(2)
1
oom错误,内存溢出了。你再仔细看下代码吧
1
无限循环导致的内存溢出。你看看自己的第二个while语句吧
