






如何编写统计查询的sql语句?
0

1.Grid表
ID NUMBER(19) --行政ID
RIBBON_CODE VARCHAR2(255 CHAR)--行政区号
TOPGRID_ID NUMBER(19) --上级行政ID
2.Material表
ID NUMBER(30) --物资ID
NAME VARCHAR2(255 CHAR) --资源名称
RESOURCE_TYPE_ID NUMBER(30) -- 资源类型ID
3.protect_entity_materials 表(主表)
ID NUMBER(30) --储备物资ID
GRID_ID NUMBER(30) -—行政区划ID
MATERIAL_MUMBER NUMBER(19,4) -—存储物资数量
MATERIAL_ID NUMBER(30) –-存储的物资ID
4.resource_type 表
ID NUMBER(19) --资源类型ID
TOP_TYPE_ID NUMBER(19) –-上级资源类型
TYPE_CODE VARCHAR2(255 CHAR) --资源代号
采用Oracle数据库,其中grid 表为行政区化表,他是递归结构的,也就是说,深圳市下面有龙岗区,罗湖区,南山区。。。,龙岗区下面又有荷坳,坳背。。。依次类推,resource_type 表资源类型表,也是递归结构也就是根类型下面还有子类型,现在比较头疼的问题就是,如何进行逐级的汇总?
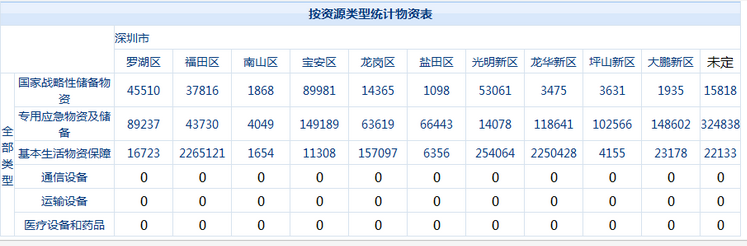
最终要查询的效果(根据物资类型进行统计,深圳市下面一共十个区,查询每个区的储备物资数量):
地区 统计 资源类型
罗湖区 45510 国家战略性储备物资
罗湖区 89237 专用应急物资及储备
罗湖区 16723 基本生活物资保障
罗湖区 0 通信设备
罗湖区 0 运输设备
罗湖区 0 医疗设备和药品
福田区 37816 国家战略性储备物资
福田区 13244 专用应急物资及储备
。 。 。
。 。 。
。 。 。
因为是采用SSRS的报表形式展现,他最后的要求呈现的结果如下图:
下面是我自己写的一些sql代码,但是是有问题的。。。
select sum(nvl(p.material_mumber,0)) as "统计",r.type_name as "物资类型",g.name as "行政区域"
from protect_entity_materials p, material m ,
(
select * from RESOURCE_TYPE r1
where exists (select * from RESOURCE_TYPE r2 where r1.top_type_id=r2.top_type_id and r2.type_code='43A00')
) r,--获取物资的根类型
(
select * from grid g1
where exists (select * from grid g2 where g1.topgrid_id=g2.topgrid_id and g2.ribbon_code='440303')
) g --获取各个区的信息
where p.grid_id in (select g3.id
from grid g3
start with g3.ribbon_code = g.ribbon_code--递归查询某一行政区域的所有子区域
connect by prior g3.id = g3.topgrid_id)
and p.material_id = m.id
and r.id = m.resource_type_id
and g.id = p.grid_id
and m.resource_type_id in
(select r3.id
from resource_type r3
start with r3.id = r.id--递归查询某一分类下的所有的子分类
connect by prior r3.id = r3.top_type_id)
group by r.type_name,g.name;
本人刚毕业,刚找到工作,小菜鸟一只,过几天老大就要我交东西了,还请前辈们多多指导一下,这个统计的sql该怎么写,小弟不胜感激!!!


最佳答案
0
我是搞sqlserver的,不过sql语句应该都是大同小异的。
我先给点思路和建议。
首先对于这种查询不应该写成一个sql语句,这种写法一般是新手出于学习的目的,比较要了解sql语句的嵌套写法,才会这么写,而实际应用中是不建议这样写的,一则是执行效率比较差,再则复杂了导致结构不清晰,不便于维护。
首先你要生成两张表
一张表的字段是:行政区ID、顶级行政区ID(指罗湖、福田这些行政区)、顶级行政区名称
另一张表的字段是:资源类型ID、顶级资源类型ID、顶级资源名称
当然这两张表可以是临时表,也可以是物理表,但是如果这个查询经常要用到,就把这两张表建成物理表,当然物理表也有不好的地方,就是这两张表是依赖你列出的1,2,4三张表的数据,所以当这三张表的数据是经常要更新的,那这两张表也需要更新。总之,用临时表还是物理表你自己根据实际情况取舍。
如果得到了这两张表,剩下的事情无非就是联表,group by这类操作了,这个对楼主来说就不是问题了。
那关键的问题就是怎么得到我说的这两张表,请楼主回复后我再继续为你解答。
深感楼主是可造之才,若明天有时间我愿意在线指导你完成!
收获园豆:150
真的,发自内心说声感谢,很抱歉今天才回复您,您方便留下您的联系方式吗?我好联系您
@狂奔的小李子: 请加扣扣2504942383
其他回答(2)
0
我看你写的sql已经涉及很多方面了
这你都能写出来,说明你不是菜鸟,已经很厉害了
你多调调代码,肯定能写出来的!
收获园豆:25
谢谢鼓励。。。正在努力调试中
0
加油,统计并不难
收获园豆:25
嗯嗯。。谢谢鼓励哦
