






请问scrapy-redis采用分布式爬取不到数据怎么办
0

采用本地redis存储,在ubuntu17.10版本运行scrapy runspider xs.py 然后再打开redis-server后连接redis-cli输入如下:

结果出现:
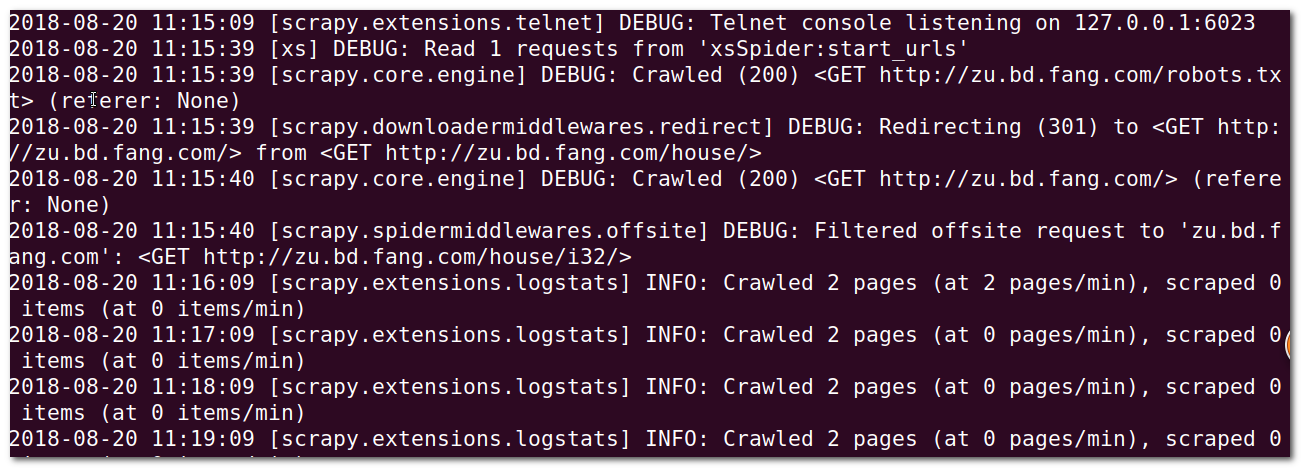 出了什么错误。
出了什么错误。
代码如下:
spider代码如下xs.py:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor # from scrapy.spiders import CrawlSpider, Rule from scrapy.spiders import Rule from scrapy_redis.spiders import RedisCrawlSpider from xiaoshuo.items import XiaoshuoItem class XsSpider(RedisCrawlSpider): name = 'xs' # allowed_domains = ['zu.bd.fang.com'] # start_urls = ['http://zu.bd.fang.com/house/'] redis_key = "xsSpider:start_urls" def __init__(self,*args,**kwargs): domain = kwargs.pop('domain','') self.allowed_domains = filter(None,domain.split(',')) super(XsSpider,self).__init__(*args,**kwargs) page_link = LinkExtractor(allow = (r'zu.bd.fang.com/house/i\d+/')) project_link = LinkExtractor(allow = (r'zu.bd.fang.com/chuzu/3_\d+_1.htm')) rules = ( Rule(page_link), Rule(project_link, callback='parse_item'), ) def parse_item(self, response): item = XiaoshuoItem() item['title'] = response.xpath('//div[@class="wid1200 clearfix"]//h1/text()')[0].extract() yield item
items.py如下:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html from scrapy import Field,Item class XiaoshuoItem(Item): # define the fields for your item here like: # name = scrapy.Field() title = Field()
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class XiaoshuoPipeline(object): def __init__(self): self.filename = open('xs.json','wb+') def process_item(self, item, spider): content = json.dumps(dict(item),ensure_ascii = False)+'\n' self.filename.write(content.encode('utf-8')) return item def close_spider(self,spider): self.filename.close()
settings.py

# -*- coding: utf-8 -*- # Scrapy settings for xiaoshuo project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'xiaoshuo' SPIDER_MODULES = ['xiaoshuo.spiders'] NEWSPIDER_MODULE = 'xiaoshuo.spiders' # 使用scrapy-redis 里的去重组件,不使用scrapy默认的去重 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis里的调度器组件,不实用scrapy默认的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 允许暂停,redis请求记录不丢失 SCHEDULER_PERSIST = True # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'xiaoshuo (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # DOWNLOAD_DELAY = 2 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'xiaoshuo.middlewares.XiaoshuoSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'xiaoshuo.middlewares.XiaoshuoDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'xiaoshuo.pipelines.XiaoshuoPipeline': 300, 'scrapy_redis.pipelines.RedisPipeline':400, } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'


所有回答(1)
1
你肯定是用Windows lpush的,直接redis-cli连接的是127.0.0.1,但是你在redis里已经改了bind了,而且你的工程里的REDIS_HOST设置的也不是这个,总之你先通过 redis-cli -h 192...*** -p 6379连接,然后再 lpush就可以了
