






python 处理csv文件的两列数据,并将对比结果写入另一列
0



所有回答(1)
0
# -*- coding: utf-8 -*-
import numpy as np
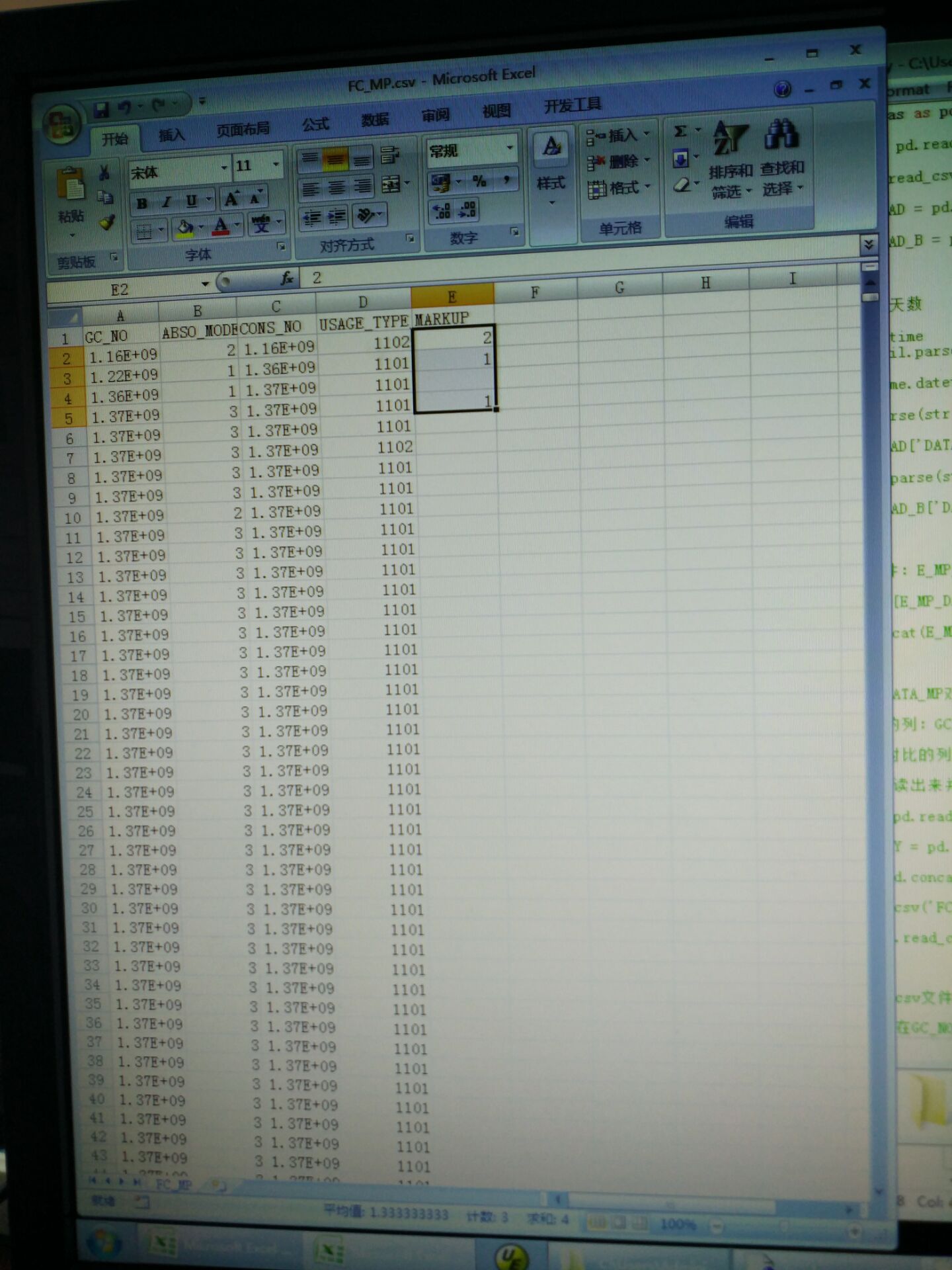
A = np.loadtxt('d:\\test.cvs', delimiter = ',', usecols = (3, 4))
rowcount = np.shape(A)[0]
B = np.zeros(rowcount).reshape(4, 1)
for i in range(rowcount):
if A[i, 0] == 1101 and (A[i, 1] == 1 or A[i, 1] == 3):
B[i, 0] = 1
elif A[i, 0] == 1102 and A[i, 1] == 2:
B[i, 0] = 2
C = np.hstack((A, B))
np.savetxt('D:\\result.cvs', C, delimiter = ',')
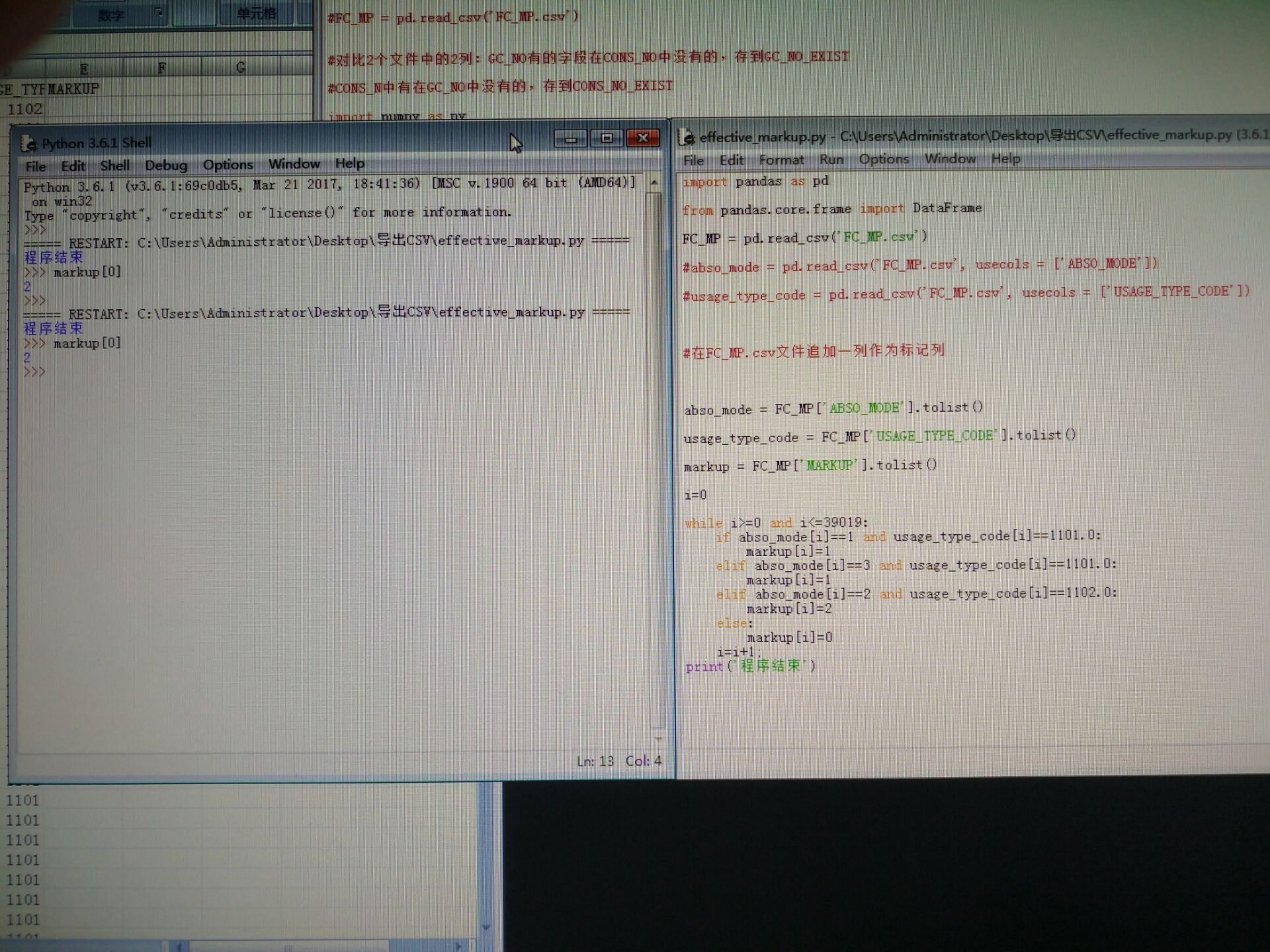
我试着用pandas写了,在脚本也能都出来,但是怎么保存到csv里第五列呢?
@ITCSJ: 我不熟悉这个,我熟悉numpy,numpy是创建一个二维数组(或矩阵),把这个数组保存成文件就可以,如果保存到第5列,那么需要创建一个n*5的二维数组,把结果放到第5列后保存成文件就好了。你用的这个也应该有这样的方法吧,比如类似save_svc这样的方法
@会长: 对的,我们的思路是一样的,只是用的函数库不一样,我再试试,谢谢你
