







求一个MS-SQL 分组统计SQL查询
0

Table
fieldA
aaaa-cc-a
bvdsv-bv-s
vdsavd-cc-a
csaccc-cc-c-c
fsafe-ff-s
csacsa-cc-a
gafff-bv-s
ff-s cc-c-c cc-a bv-s cc-a 这些是未知的,唯一特点就是第一个"-"后面的值。
需要得到的数据就是分组统计-后面数据有多少
最后统计得到的数据
cc-a 2
bv-s 2
cc-a 1
cc-c-c 1
ff-s 1
问题补充:
谢谢各位了,已经找到解决方案了!!!
非常感谢各位!!!
SET QUOTED_IDENTIFIER ON
GO
--创建函数
Create FUNCTION [dbo].[GetSubStrBySpint]
(
@String NVARCHAR(300),
@split NVARCHAR(10)
)
RETURNS NVARCHAR(1024)
AS
BEGIN
DECLARE @location INT
DECLARE @start INT
DECLARE @seed INT
SET @String = LTRIM(RTRIM(@String))
SET @start = CHARINDEX(@split, @String)
SET @seed = LEN(@split)
SET @start += @seed
SET @location = LEN(@String) - @start + @seed
RETURN SUBSTRING(@String, @start, @location)
END
我自己写了个函数
然后在查询就好了
谢谢各位!!!
然后直接调用
select * from (select dbo.GetSubStrBySpint([fieldA] , '.') as hz,count(1) as num from Table group by dbo.GetSubStrBySpint([fieldA] , '.')) as c order by c.num desc


最佳答案
0
其他回答(3)
0
如果可以的话,可以将fieldA拆分成2个字段:前缀、后缀
收获园豆:5
0
group by right(col,charindex('-',col),len(col)-charindex('-',col))
大概意思,可能边界上有差别,你需要调试一下。
收获园豆:5
1
哈哈,小兄弟结贴好快,我刚写好demo准备发你的。思路和你写的函数一样,不过没有写那么复杂,写的简洁版,如图:
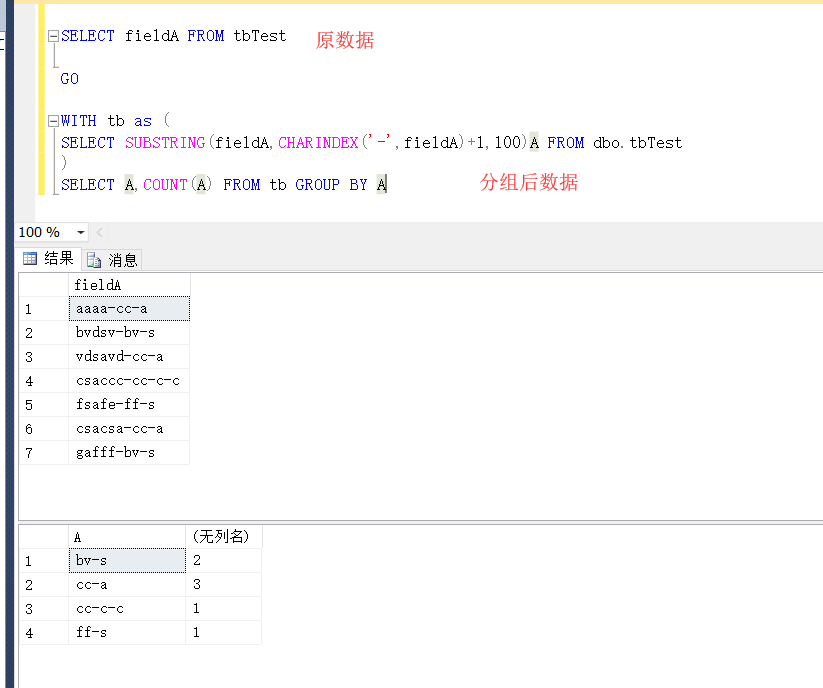
谢谢!!!
