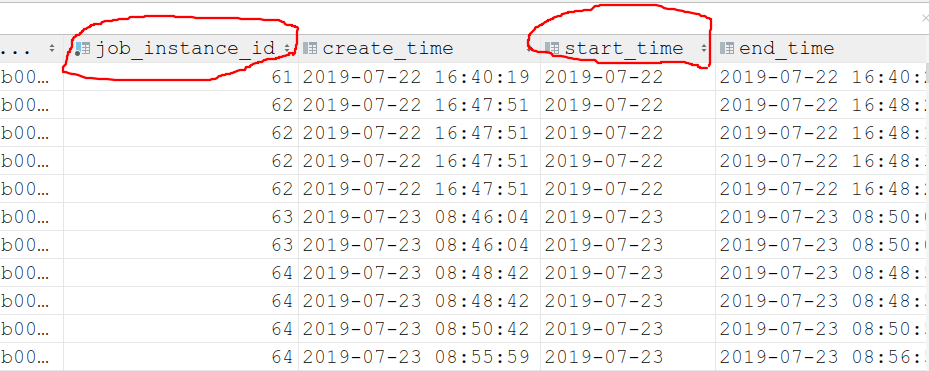
现在在写一个sqlalchemy的语句,就是以一个表里面的两个字段去重,如下图,以job_instance_id ,和start_time两个值去重,就是这两个值不能一样,其它的字段值可以一样,表名是job_execution,请问有会的吗?!
就是去重的时候不用根据具体的值,如job_instance_id=62 and_ start_time=2019-07-02,而是要自动去重;我现在的查询语句是这样的job_excutions = JobExecution.query.filter( JobExecution.job_instance_id.in_(task_ids) ).order_by(db.desc(JobExecution.id)).distinct(),后面我会用job_excutions去用pagination分页,分完页之后发现有重复数据,再去重的话就会导致每页的数据数量不一样(因为本来一页有十个数据,去完重还有三个,但是它还是占据一页),所以要想用pagination方法分页就必须在用这个方法之前保证数据的唯一,但现在数据库有好多重复数据,怎么去重呢 ?我也试过不用pagination这个分页方法,而是自己些分页,但是由于数据量太大,需要循环整个查询出来的数据,导致系统比较慢,所以只能用sqlalchemy去重,这样应该可以保证速度快,分页不会出错。
最后使用with_entities和group_by解决。










就是去重的时候不用根据具体的值,如job_instance_id=62 and_ start_time=2019-07-02,而是要自动去重;我现在的查询语句是这样的job_excutions = JobExecution.query.filter( JobExecution.job_instance_id.in_(task_ids) ).order_by(db.desc(JobExecution.id)).distinct(),后面我会用job_excutions去用pagination分页,分完页之后发现有重复数据,再去重的话就会导致每页的数据数量不一样(因为本来一页有十个数据,去完重还有三个,但是它还是占据一页),所以要想用pagination方法分页就必须在用这个方法之前保证数据的唯一,但现在数据库有好多重复数据,怎么去重呢 ?我也试过不用pagination这个分页方法,而是自己些分页,但是由于数据量太大,需要循环整个查询出来的数据,导致系统比较慢,所以只能用sqlalchemy去重,这样应该可以保证速度快,分页不会出错。
– 奈何技术不达标 6年前