






MPI并行计算——矩阵相乘
0
[待解决问题]

问题描述
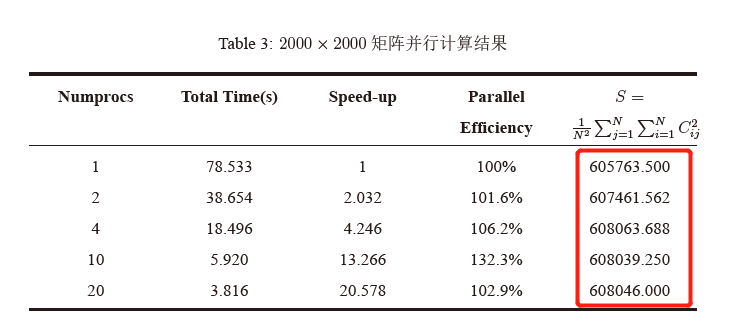
利用MPI以及Fortran完成矩阵的并行计算,但为什么使用不同线程数计算结果有很大差别呢?萌新小白,向大佬们求助!代码如下:
'''Fortran
program Matrix_operation
implicit none
include 'mpif.h'
integer, parameter::N=1000 !矩阵大小
real *8::Time_begin, Time_end !计算时间
integer myid, ierr, numprocs, status(MPI_STATUS_SIZE)
integer NP !NP=N/numprocs
real x, y, sum_local, sum_global
integer i, j, k
integer step, id_send, id_recv
!每个进程中的动态数组,配合MPI_Comm_size使用,即可以不用事先知道进程数
real,dimension(:,:),allocatable::A_k, B_k, C_k, B_temp
call MPI_Init(ierr)
!开始时间
Time_begin=MPI_Wtime()
call MPI_Comm_Rank(MPI_COMM_WORLD, myid, ierr)!得到当前进程标识符
call MPI_Comm_size(MPI_COMM_WORLD, numprocs, ierr)!得到通讯域包含的进程数
if(myid .eq. 0) print*, 'numprocs=',numprocs
NP=N/numprocs
allocate(A_k(NP,N), B_k(N,NP), C_k(NP,N), B_temp(N,NP))
!矩阵A_k(NP,N)赋值
do i=1, NP
x=(REAL(i)+REAL(NP)*myid-1.0)/(REAL(N)-1.0)
do j=1,N
y=(REAL(j)-1.0)/(REAL(N)-1.0)
A_k(i,j)=exp(y)*sin(3.0*x)
enddo
enddo
!矩阵B_k(N,NP)赋值
do i=1, N
x=(REAL(i)-1.0)/(REAL(N)-1.0)
do j=1,NP
y=(REAL(j)+REAL(NP)*myid-1)/(REAL(N)-1)
B_k(i,j)=(x+cos(4.0*x))*(1.0+y)
enddo
enddo
!“全收集”思路,进行按节拍循环发送数据
do step=0, numprocs-1
id_send=myid+step;if(id_send .ge. numprocs) id_send=id_send-numprocs
id_recv=myid-step;if(id_recv .lt. 0) id_recv=id_recv+numprocs
call MPI_Sendrecv(B_k, N*NP, MPI_REAL, id_send, 99, B_temp, N*NP, &
MPI_REAL, id_recv, 99, MPI_COMM_WORLD, status, ierr)
!计算C_k矩阵
do i=1,NP
do j=1,NP
C_k(i,NP*id_recv+j)=0
do k=1,N
C_k(i,NP*id_recv+j)=C_k(i,NP*id_recv+j)+A_k(i,k)*B_temp(k,j)
enddo
enddo
enddo
enddo
!求S的值
sum_local=0
do i=1,NP
do j=1,N
sum_local=sum_local+C_k(i,j)*C_k(i,j)
enddo
enddo
!print*, 'myid=',myid, 'S_local=',sum_local
!类似上一题的规约求和
call MPI_Reduce(sum_local,sum_global,1,MPI_REAL, &
MPI_SUM,0,MPI_COMM_WORLD,ierr)
if(myid .eq. 0) print*, 'S=',sum_global/(REAL(N)*REAL(N))
!程序运行时间
call MPI_Barrier(MPI_COMM_WORLD,ierr)
Time_end=MPI_Wtime()
if(myid .eq. 0) print*, 'Total time:', Time_end-Time_begin
call MPI_Finalize(ierr)
end program Matrix_operation
'''

所有回答(1)
0
太厉害了大佬
