






8086汇编实现快速排序debug
0

我是照着C语言的快排,挨行实现的。
int partition(int* Arr, int left, int right)
{
int pivot = Arr[left];
while (left < right) //left_smaller_right
{
while (pivot <= Arr[right] && left < right) // t2_1 t2_2
{
//compareTimes++;
right--; // right_minus_1
}
if (left != right) // t3
{
Arr[left] = Arr[right]; // swap_1
//swapTimes++;
left++;
}
while (Arr[left] <= pivot && left < right) // t4_1 t4_2
{
//compareTimes++;
left++; // left_plus_1
}
if (left != right) // t5
{
Arr[right] = Arr[left]; // swap_2
//swapTimes++;
right--;
}
}
Arr[left] = pivot; // get_pivot
return left;
}
void quickSort(int* Arr, int lower, int upper)
{
int pivot = partition(Arr, lower, upper);
if (lower < pivot) // v1
{
quickSort(Arr, lower, pivot - 1);
//recursionTimes++;
}
if (pivot < upper) // v2
{
quickSort(Arr, pivot + 1, upper);
//recursionTimes++;
}
}
下面这是我写的8086汇编代码,与快排有关的两个函数写有注释,其他函数都比较简单,见名知意,与我的问题关系不大。
stack segment stack
db 512 dup(?)
stack ends
data segment
arr dw 10, 9, 23, 5, 88
string1 db "Press any key to continue!", 0ah, 0dh, '$'
string2 db "Before sort:", 0ah, 0dh, '$'
string3 db "After sort:", 0ah, 0dh, '$'
msg db "Here!", 0ah, 0dh, '$'
data ends
code segment
assume ds: data, cs: code, ss: stack
main:
mov ax, stack
mov ss, ax
mov ax, data
mov ds, ax
; test 1
;lea ax, arr
;push ax
;mov ax, 0
;push ax
;mov ax, 8
;push ax
;call far ptr partition
;push ax
;call far ptr dispsiw
;call far ptr lineFeed
lea dx, string1
mov ah, 09h
int 21h
lea ax, arr
push ax
mov ax, 5
push ax
call far ptr print_arr
call far ptr lineFeed
pop ax
pop ax
lea ax, arr
push ax
mov ax, 0
push ax
mov ax, 8
push ax
call far ptr quickSort
pop ax
pop ax
pop ax
lea dx, string1
mov ah, 09h
int 21h
lea ax, arr
push ax
mov ax, 5
push ax
call far ptr print_arr
call far ptr lineFeed
pop ax
pop ax
jmp done
;[bp + 10] -- right
;[bp + 12] -- left
;[bp + 14] -- Arr[]
partition proc far
push bp
push si
push di
mov bp, sp
; [di]{k} -- Arr[k/2]
mov si, [bp + 14]
xor di, di
mov bx, [bp + 12]
and bx, 1
cmp bx, 1
je left_is_odd
jmp left_is_even
left_is_odd:
mov bx, [bp + 12]
add bx, 1
mov [bp + 12], bx
;jmp left_is_even
left_is_even:
mov bx, [bp + 10]
and bx, 1
cmp bx, 1
je right_is_odd
jmp right_is_even
right_is_odd:
mov bx, [bp + 10]
add bx, 1
mov [bp + 10], bx
;jmp right_is_even
right_is_even:
mov bx, [bp + 12] ; bx -- left
mov ax, [di + bx] ; ax -- pivot
;
; debugging
;mov bx, [bp + 10]
;mov ax, [di + bx]
;call far ptr dispsiw
;
mov dx, [bp + 10] ; dx -- right
;
; debugging
;mov ax, bx
;call far ptr dispsiw
;jmp partition_done
;
cmp bx, dx
jl left_smaller_right ; left < right
jmp partition_done
left_smaller_right:
jmp t2_1
t2_1:
mov bx, [bp + 10] ; bx -- right
mov dx, [di + bx] ; dx -- Arr[right]
cmp ax, dx ; pivot <= Arr[right]
jng t2_2 ; jle
jmp t3
t2_2:
mov bx, [bp + 12] ; bx -- left
mov dx, [bp + 10] ; dx -- right
cmp bx, dx ; left < right
jl right_minus_1
jmp t3
right_minus_1:
mov dx, [bp + 10] ; dx -- right
dec dx
mov [bp + 10], dx ; right--;
;jmp t3
t3:
mov bx, [bp + 12] ; bx -- left
mov dx, [bp + 10] ; dx -- right
cmp bx, dx ; left != right
jne swap_1
jmp t4_1
swap_1:
mov bx, [bp + 10] ; bx -- right
mov dx, [di + bx] ; dx -- Arr[right]
mov bx, [bp + 12] ; bx -- left
mov [di + bx], dx ; [di + bx] -- Arr[left], Arr[left] <= Arr[right];
mov bx, [bp + 12] ; bx -- left
inc bx
mov [bp + 12], bx ; left++
;jmp t4_1
t4_1:
mov bx, [bp + 12] ; bx -- left
mov dx, [di + bx] ; dx -- Arr[left]
cmp dx, ax
jng t4_2 ; jle
jmp t5
t4_2:
mov bx, [bp + 12] ; bx -- left
mov dx, [bp + 10] ; dx -- right
cmp bx, dx ; left < right
jl left_plus_1
jmp t5
left_plus_1:
mov bx, [bp + 12] ; bx -- left
inc bx
mov [bp + 12], bx ; left++
;jmp t5
t5:
mov bx, [bp + 12] ; bx -- left
mov dx, [bp + 10] ; dx -- right
cmp bx, dx ; left != right
jne swap_2
jmp get_pivot
swap_2:
mov bx, [bp + 12] ; bx -- left
mov dx, [di + bx] ; dx -- Arr[left]
mov bx, [bp + 10] ; bx -- right
mov [di + bx], dx ; [di + bx] -- Arr[right], Arr[right] <= Arr[left];
mov bx, [bp + 10] ; bx -- right
inc bx
mov [bp + 10], bx ; right++
;jmp get_pivot
get_pivot:
mov bx, [bp + 12] ; bx -- left
mov [di + bx], ax ; Arr[left] <= pivot
jmp partition_done
partition_done:
mov ax, [bp + 12] ; ax -- left
pop di
pop si
pop bp
ret
partition endp
;[bp + 10] -- upper
;[bp + 12] -- lower
;[bp + 14] -- Arr[]
quickSort proc far
push bp
push si
push di
mov bp, sp
; [di]{k} -- Arr[k/2]
mov si, [bp + 14]
xor di, di
mov bx, [bp + 10] ; bx -- upper
and bx, 1
cmp bx, 1
je lower_is_odd
jmp lower_is_even
lower_is_odd:
mov bx, [bp + 10] ; bx -- upper
add bx, 1
mov [bp + 10], bx
;jmp lower_is_even
lower_is_even:
mov bx, [bp + 12] ; bx -- lower
and bx, 1
cmp bx, 1
je upper_is_odd
jmp upper_is_even
upper_is_odd:
mov bx, [bp + 12] ; bx -- lower
add bx, 1
mov [bp + 12], bx
;jmp upper_is_even
upper_is_even:
mov ax, [bp + 14] ; ax -- Arr
push ax
mov ax, [bp + 12] ; ax -- lower
push ax
mov ax, [bp + 10] ; ax -- upper
push ax
call far ptr partition
mov dx, ax
pop bx
pop bx
pop bx
jmp v1
v1:
mov ax, dx ; ax -- pivot
mov bx, [bp + 12] ; bx -- lower
mov dx, ax ; dx -- pivot
cmp bx, ax
jl lower_smaller_pivot ; lower(bx) < pivot(ax)
jmp v2
lower_smaller_pivot:
mov ax, [bp + 14] ; ax -- Arr
push ax
mov ax, [bp + 12] ; ax -- lower
push ax
mov ax, dx ; ax -- pivot
dec ax ; ax -- pivot - 1
push ax
call far ptr quickSort
pop bx
pop bx
pop bx
v2:
mov ax, dx ; ax -- pivot
mov bx, [bp + 10] ; bx -- upper
cmp ax, bx
jl pivot_smaller_upper ; pivot(ax) < upper(bx)
jmp quickSort_done
pivot_smaller_upper:
mov ax, [bp + 14] ; ax -- Arr
push ax
mov ax, dx ; ax -- pivot
inc ax ; pivot + 1
push ax
mov ax, [bp + 10] ; ax -- upper
push ax
call far ptr quickSort
pop bx
pop bx
pop bx
quickSort_done:
pop di
pop si
pop bp
ret
quickSort endp
read_arr proc far
push bp
push si
push di
mov bp, sp
mov si, [bp]
xor di, di
mov cx, [bp+10]
readArr:
call far ptr readsiw
mov [di], ax
add di, 2
loop readArr
pop di
pop si
pop bp
ret
read_arr endp
print_arr proc far
push bp
push si
push di
mov bp,sp
mov si, [bp]
xor di, di
mov cx, [bp+10]
printArr:
mov ax, [di]
call far ptr dispsiw
;call far ptr lineFeed
call far ptr space
add di, 2
loop printArr
pop di
pop si
pop bp
ret
print_arr endp
readsiw proc far
push bx
push cx
push dx
xor bx, bx
xor cx, cx
mov ah, 1
int 21h
cmp al, '+'
jz rsiw1
cmp al, '-'
jnz rsiw2
mov cx, -1
rsiw1:
mov ah, 1
int 21h
rsiw2:
cmp al, '0'
jb rsiw3
cmp al, '9'
ja rsiw3
sub al, 30h
xor ah, ah
shl bx, 1
mov dx, bx
shl bx, 1
shl bx, 1
add bx, dx
add bx, ax
jmp rsiw1
rsiw3:
cmp cx, 0
jz rsiw4
neg bx
rsiw4:
mov ax, bx
pop dx
pop cx
pop bx
ret
readsiw endp
dispsiw proc far
push ax
push bx
push dx
test ax, ax
jnz dsiw1
mov dl, '0'
mov ah, 2
int 21h
jmp dsiw5
dsiw1:
jns dsiw2
mov bx, ax
mov dl, '-'
mov ah, 2
int 21h
mov ax, bx
neg ax
dsiw2:
mov bx, 10
push bx
dsiw3:
cmp ax, 0
jz dsiw4
xor dx, dx
div bx
add dl, 30h
push dx
jmp dsiw3
dsiw4:
pop dx
cmp dl, 10
je dsiw5
mov ah, 2
int 21h
jmp dsiw4
dsiw5:
pop dx
pop bx
pop ax
ret
dispsiw endp
lineFeed proc far
push ax
push dx
mov dl, 0dh
mov ah, 2
int 21h
mov dl, 0ah
mov ah, 2
int 21h
pop dx
pop ax
ret
lineFeed endp
space proc far
pushf
push ax
push dx
mov ah,02h
mov dl,' '
int 21h
pop dx
pop ax
popf
ret
space endp
done:
lea dx, string1
mov ah, 09h
int 21h
mov ah, 07h
int 21h
mov ah, 4ch
int 21h
code ends
end main
我预期程序可以实现从小到大排序,但结果显然不对。如果有懂的热心大佬,还望指教!!!
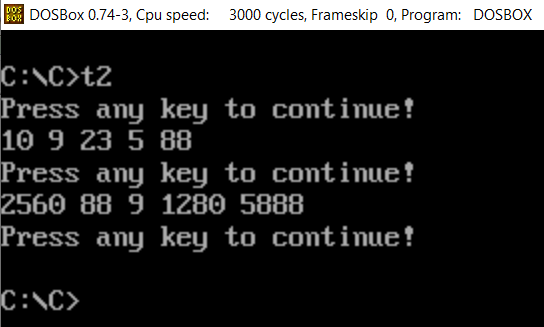


所有回答(1)
-1
我这里使用工具对C语言的代码进行了反汇编,结果如下
partition(int*, int, int):
push rbp
mov rbp, rsp
mov QWORD PTR [rbp-24], rdi
mov DWORD PTR [rbp-28], esi
mov DWORD PTR [rbp-32], edx
mov eax, DWORD PTR [rbp-28]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov eax, DWORD PTR [rax]
mov DWORD PTR [rbp-4], eax
jmp .L2
.L5:
sub DWORD PTR [rbp-32], 1
.L3:
mov eax, DWORD PTR [rbp-32]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov eax, DWORD PTR [rax]
cmp DWORD PTR [rbp-4], eax
jg .L4
mov eax, DWORD PTR [rbp-28]
cmp eax, DWORD PTR [rbp-32]
jl .L5
.L4:
mov eax, DWORD PTR [rbp-28]
cmp eax, DWORD PTR [rbp-32]
je .L7
mov eax, DWORD PTR [rbp-32]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov edx, DWORD PTR [rbp-28]
movsx rdx, edx
lea rcx, [0+rdx*4]
mov rdx, QWORD PTR [rbp-24]
add rdx, rcx
mov eax, DWORD PTR [rax]
mov DWORD PTR [rdx], eax
add DWORD PTR [rbp-28], 1
jmp .L7
.L9:
add DWORD PTR [rbp-28], 1
.L7:
mov eax, DWORD PTR [rbp-28]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov eax, DWORD PTR [rax]
cmp DWORD PTR [rbp-4], eax
jl .L8
mov eax, DWORD PTR [rbp-28]
cmp eax, DWORD PTR [rbp-32]
jl .L9
.L8:
mov eax, DWORD PTR [rbp-28]
cmp eax, DWORD PTR [rbp-32]
je .L2
mov eax, DWORD PTR [rbp-28]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rax, rdx
mov edx, DWORD PTR [rbp-32]
movsx rdx, edx
lea rcx, [0+rdx*4]
mov rdx, QWORD PTR [rbp-24]
add rdx, rcx
mov eax, DWORD PTR [rax]
mov DWORD PTR [rdx], eax
sub DWORD PTR [rbp-32], 1
.L2:
mov eax, DWORD PTR [rbp-28]
cmp eax, DWORD PTR [rbp-32]
jl .L3
mov eax, DWORD PTR [rbp-28]
cdqe
lea rdx, [0+rax*4]
mov rax, QWORD PTR [rbp-24]
add rdx, rax
mov eax, DWORD PTR [rbp-4]
mov DWORD PTR [rdx], eax
mov eax, DWORD PTR [rbp-28]
pop rbp
ret
quickSort(int*, int, int):
push rbp
mov rbp, rsp
sub rsp, 32
mov QWORD PTR [rbp-24], rdi
mov DWORD PTR [rbp-28], esi
mov DWORD PTR [rbp-32], edx
mov edx, DWORD PTR [rbp-32]
mov ecx, DWORD PTR [rbp-28]
mov rax, QWORD PTR [rbp-24]
mov esi, ecx
mov rdi, rax
call partition(int*, int, int)
mov DWORD PTR [rbp-4], eax
mov eax, DWORD PTR [rbp-28]
cmp eax, DWORD PTR [rbp-4]
jge .L13
mov eax, DWORD PTR [rbp-4]
lea edx, [rax-1]
mov ecx, DWORD PTR [rbp-28]
mov rax, QWORD PTR [rbp-24]
mov esi, ecx
mov rdi, rax
call quickSort(int*, int, int)
.L13:
mov eax, DWORD PTR [rbp-4]
cmp eax, DWORD PTR [rbp-32]
jge .L15
mov eax, DWORD PTR [rbp-4]
lea ecx, [rax+1]
mov edx, DWORD PTR [rbp-32]
mov rax, QWORD PTR [rbp-24]
mov esi, ecx
mov rdi, rax
call quickSort(int*, int, int)
.L15:
nop
leave
ret
我到时后再看看有什么问题
不懂别乱回复,我写的是8086不是32位Intel。
