






[爬虫]网页源码与审查模式看到的代码顺序不一致
0




所有回答(1)
0
你跟着正序的方式 去实现就行了(细节自己想)。
这不算什么,记得那个快手是自定义字体,编码自定义(也就是你获取的到内容都是乱码)。
现在一些网站都是登录一个信息,没登录随机信息。
最狠的阿里的验证码,很难解。
建议:通常爬虫既没有技术含量(没有可玩性),还涉嫌违法,谨慎代码,另辟路径。学技术的同时务必学法。
我是用requests库去获取网站响应,获得的响应是和网站源码一致的。但是实际浏览网页中,网站出现的文字是将源码里的内容按书的内容排序好再显示。
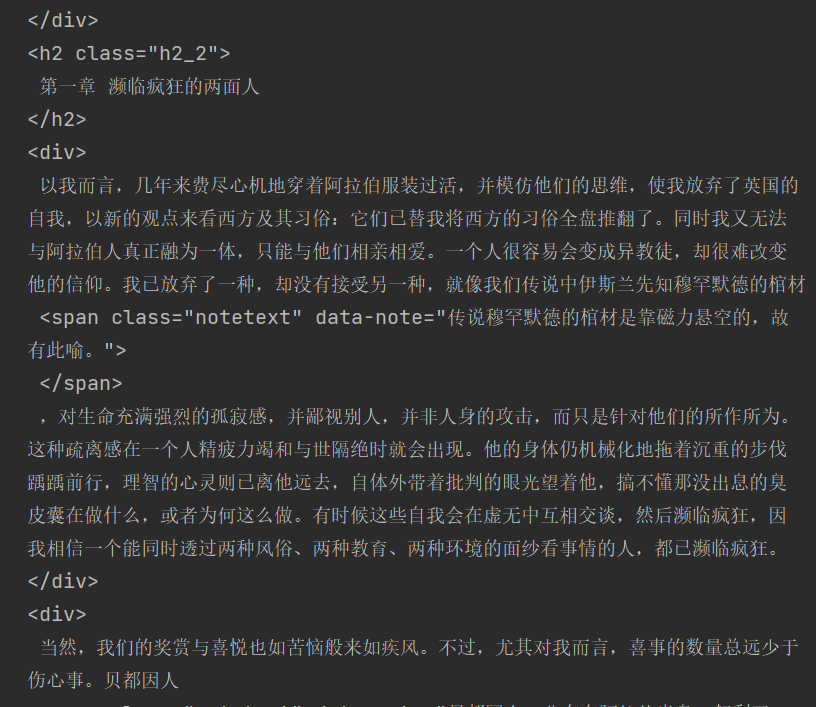
(获取的响应)

(实际观看效果)
希望大神能给我个大概的方向让我自己去摸索解决这个问题。
谢谢您的建议!学爬虫是我个人的兴趣使然,爬取网站时我也会浏览网站robots.txt文件,不会做些违法的事情。
