







sql如何判断手机号半年内是否重复出现
0

比如有一张用户记录表

写sql判断是否半年内重复出现,最后呈现的结果
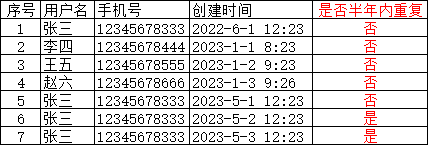
注:序号为5的不算重复,因为对比第1条时间已经过了半年
有尝试过用group by
select phone,count(*) from user_record where create_time>DATE_SUB(create_time, INTERVAL 6 MONTH) group by phone
但结果不对
phone count(*)
12345678333 4
12345678444 1
12345678555 1
12345678666 1
望各位大佬不吝赐教!
附:建表及插入数据sql
-- ----------------------------
-- Table structure for user_record
-- ----------------------------
DROP TABLE IF EXISTS `user_record`;
CREATE TABLE `user_record` (
`id` bigint NOT NULL,
`user` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`phone` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`create_time` datetime(0) NULL DEFAULT NULL,
`remark` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user_record
-- ----------------------------
INSERT INTO `user_record` VALUES (1, '张三', '12345678333', '2022-06-01 12:23:00', NULL);
INSERT INTO `user_record` VALUES (2, '李四', '12345678444', '2023-01-01 08:23:00', NULL);
INSERT INTO `user_record` VALUES (3, '王五', '12345678555', '2023-01-02 09:23:00', NULL);
INSERT INTO `user_record` VALUES (4, '赵六', '12345678666', '2023-01-03 09:26:00', NULL);
INSERT INTO `user_record` VALUES (5, '张三', '12345678333', '2023-05-01 12:23:00', NULL);
INSERT INTO `user_record` VALUES (6, '张三', '12345678333', '2023-05-02 12:23:00', NULL);
INSERT INTO `user_record` VALUES (7, '张三', '12345678333', '2023-05-03 12:23:00', NULL);


最佳答案
1
可以通过子查询实现
select phone, exists(select 1 from user_record B where B.phone = A.phone and B.id <> A.id and B.create_time>DATE_SUB(A.create_time, INTERVAL 6 MONTH) LIMIT 1) as duplicated from user_record A;
输出
phone duplicated
12345678333 1
12345678444 0
12345678555 0
12345678666 0
12345678333 1
12345678333 1
12345678333 1
收获园豆:40
感谢dudu大佬帮忙解答!
但结果没有符合预期喔,最后查询的结果需要是这样
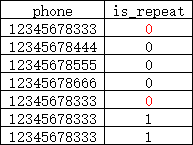
另外经测试发现,create_time>DATE_SUB(create_time, INTERVAL 6 MONTH)这个时间限制条件并不能起作用,无论是dudu大佬的方法,还是用group by
@cwzy8: 2022-05-01 12:23:00 与 2022-06-01 12:23:00 为什么不算半年内重复?
@dudu: 不好意思,我给的数据有问题,序号为5、6、7的数据创建时间应该在2023年的!
正确的建表及插入数据sql是:
DROP TABLE IF EXISTS `user_record`;
CREATE TABLE `user_record`
(
`id` bigint NOT NULL
,`user` varchar(100)
,`phone` varchar(100)
,`create_time` datetime(0)
,`remark` varchar(255)
);
INSERT INTO `test`.`user_record` (`id`, `user`, `phone`, `create_time`, `remark`) VALUES (1, '张三', '12345678333', '2022-06-01 12:23:00', NULL);
INSERT INTO `test`.`user_record` (`id`, `user`, `phone`, `create_time`, `remark`) VALUES (2, '李四', '12345678444', '2023-01-01 08:23:00', NULL);
INSERT INTO `test`.`user_record` (`id`, `user`, `phone`, `create_time`, `remark`) VALUES (3, '王五', '12345678555', '2023-01-02 09:23:00', NULL);
INSERT INTO `test`.`user_record` (`id`, `user`, `phone`, `create_time`, `remark`) VALUES (4, '赵六', '12345678666', '2023-01-03 09:26:00', NULL);
INSERT INTO `test`.`user_record` (`id`, `user`, `phone`, `create_time`, `remark`) VALUES (5, '张三', '12345678333', '2023-05-01 12:23:00', NULL);
INSERT INTO `test`.`user_record` (`id`, `user`, `phone`, `create_time`, `remark`) VALUES (6, '张三', '12345678333', '2023-05-02 12:23:00', NULL);
INSERT INTO `test`.`user_record` (`id`, `user`, `phone`, `create_time`, `remark`) VALUES (7, '张三', '12345678333', '2023-05-03 12:23:00', NULL);
问题描述中的数据也已修改,非常抱歉!
感谢dudu大佬!经测试 where条件后面再加上 and B.create_time<=A.create_time
select phone
, exists(select 1 from user_record B where B.phone = A.phone and B.id <> A.id
and B.create_time>DATE_SUB(A.create_time, INTERVAL 6 MONTH) and B.create_time<=A.create_time LIMIT 1) as duplicated
from user_record A;
得到的结果就符合了!
phone duplicated
12345678333 0
12345678444 0
12345678555 0
12345678666 0
12345678333 0
12345678333 1
12345678333 1
@cwzy8: 赞!
其他回答(1)
0
首先感谢dudu大佬的答疑解惑!根据大佬的解答及经进一步测试和完善,最终得到了答案!
核心SQL
select phone
, exists(select 1 from user_record B where B.phone = A.phone and B.id <> A.id
and B.create_time>DATE_SUB(A.create_time, INTERVAL 6 MONTH) and B.create_time<=A.create_time LIMIT 1) as duplicated
from user_record A;
因实际的数据库环境是hive,不支持上面的语法(exists),于是弄了个兼容版本:
select t1.*,if(t2.id is not null,1,0) as is_repeat
FROM user_record t1
left join
(select a.id from user_record B inner join user_record A
on B.phone = A.phone where 1=1 and B.id <> A.id and B.create_time>DATE_SUB(A.create_time, INTERVAL 6 MONTH) and B.create_time<=A.create_time group by a.id) t2
on t1.id=t2.id
再次感谢dudu大佬的帮助!
