






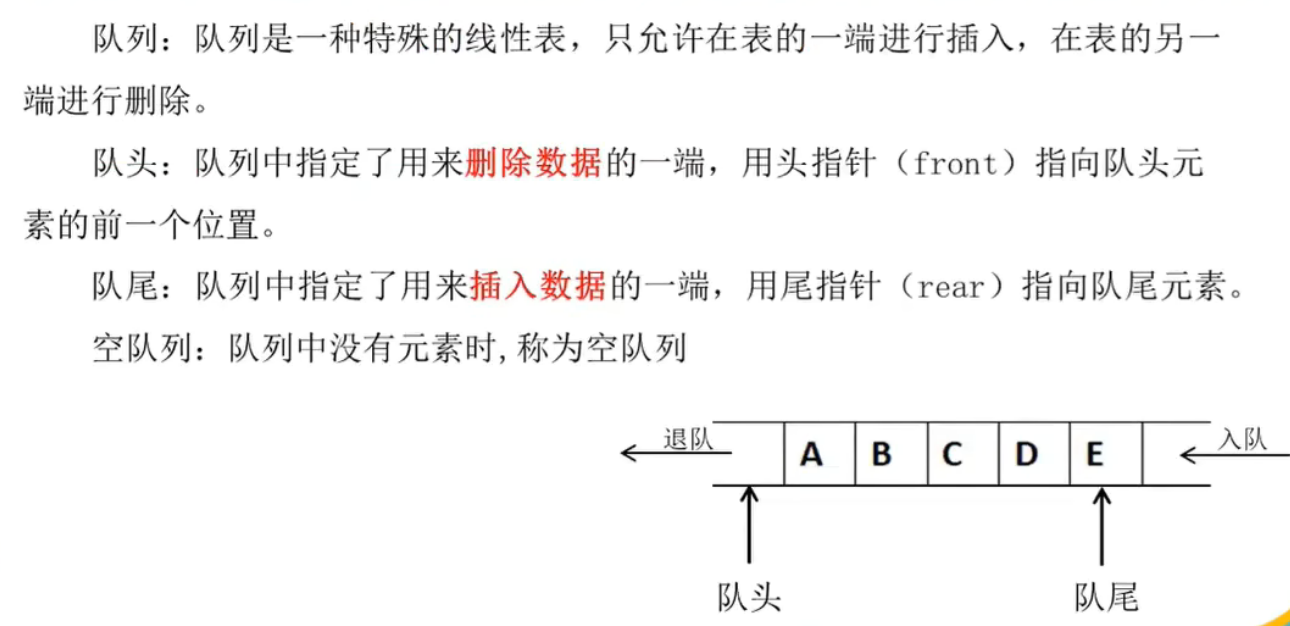
栈和队列----
0
[已解决问题]
解决于 2025-09-14 09:24

栈和队列----知识框架,栈只能在一端增加删除



顺序栈用数组做物理载体,再额外加一条“栈顶指针”规则,才变成“栈”,顺序栈:


咋一看上面ppt感觉不对:top=-1,bottom=0,才是栈空,没有元素时,栈顶“悬空”,所以给 top = -1。注意前提是bottom>=1

栈的长度是50,从1到50,同时栈空时候bottom=top=51,说明从大到小入栈,没插入一个数,top(新)=top(老)-1
所以是:|top-bottom|+1 = 31 ,A
不要纠结bottom,bottom在栈空时确实和top一样,但是插入一个元素后,从此之后,bottom永远指向最后一个元素,空栈时必须用一个特殊值(-1 或 NULL)来告诉自己和程序:
“现在没有元素,bottom 无效”。
顺序栈一般不“共享”,程序员显式地把它设计成“多栈共享同一块连续空间”,否则它就是独占一段固定数组,谁的就是谁的。“一次性整块、连续、独占”
链栈可以多个栈共享存储空间,链栈只是 一个个零散地拿节点,于是客观上实现了最细粒度、最灵活的共享与复用。




最佳答案
0
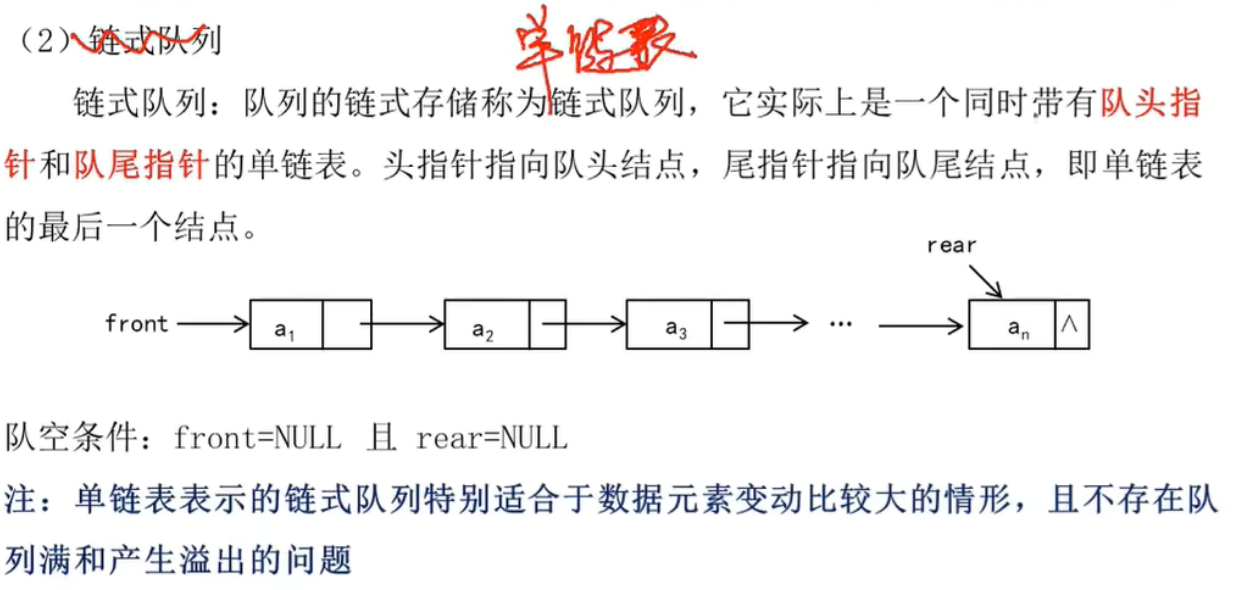
链式队列:
栈空状态不一定front=rear=NULL,当然可以自己约定,如下提:
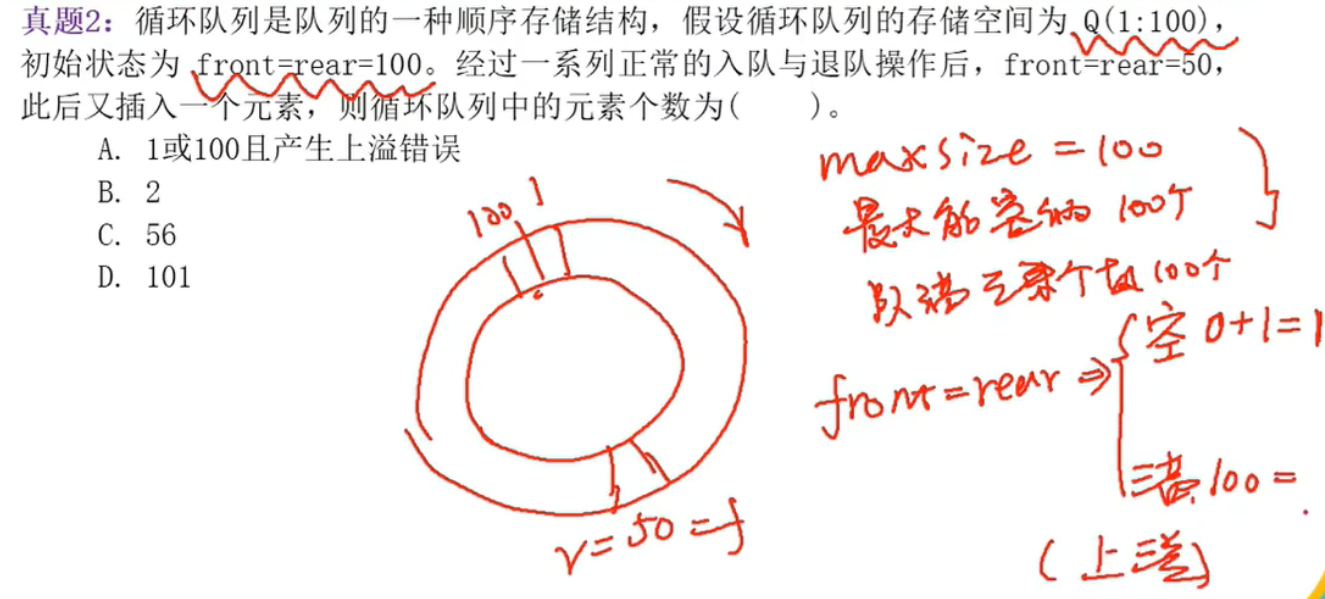
上题答案为A
1. 题目给的条件
-
存储空间:Q(1:100) → 容量 100
-
初始:front = rear = 100 → 约定空
-
若干操作后:front = rear = 50 → 仍约定空
-
再插入 1 个元素 → 必然溢出(因为队列里本来就没有空位)
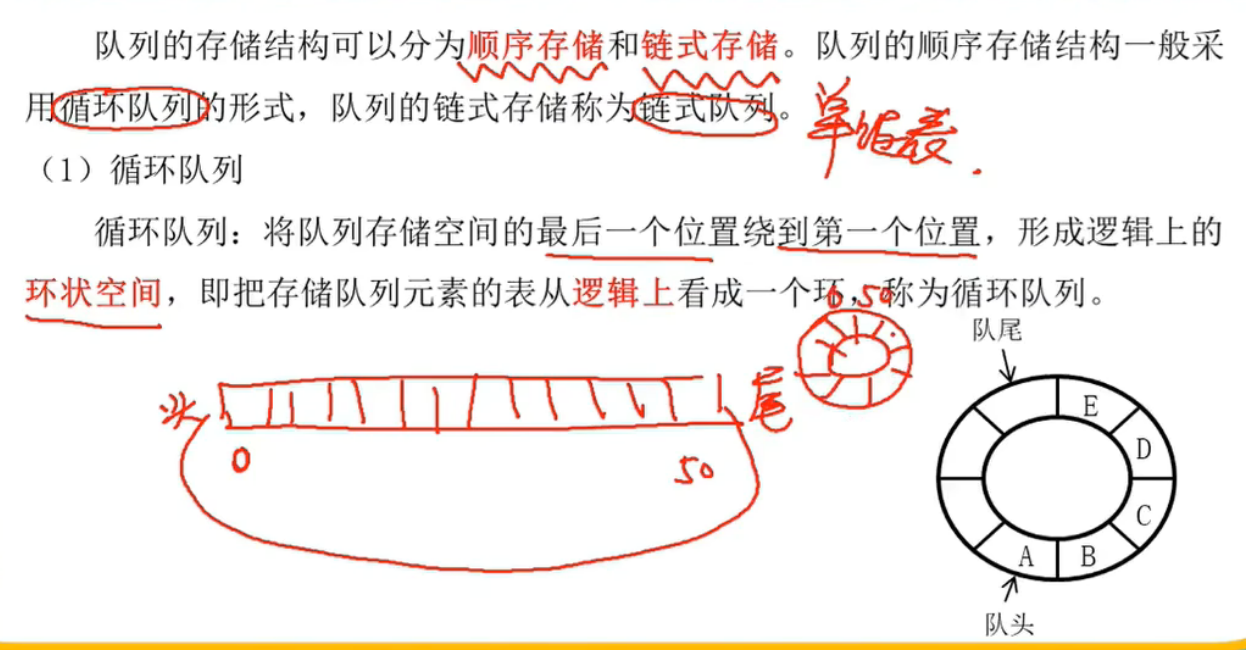
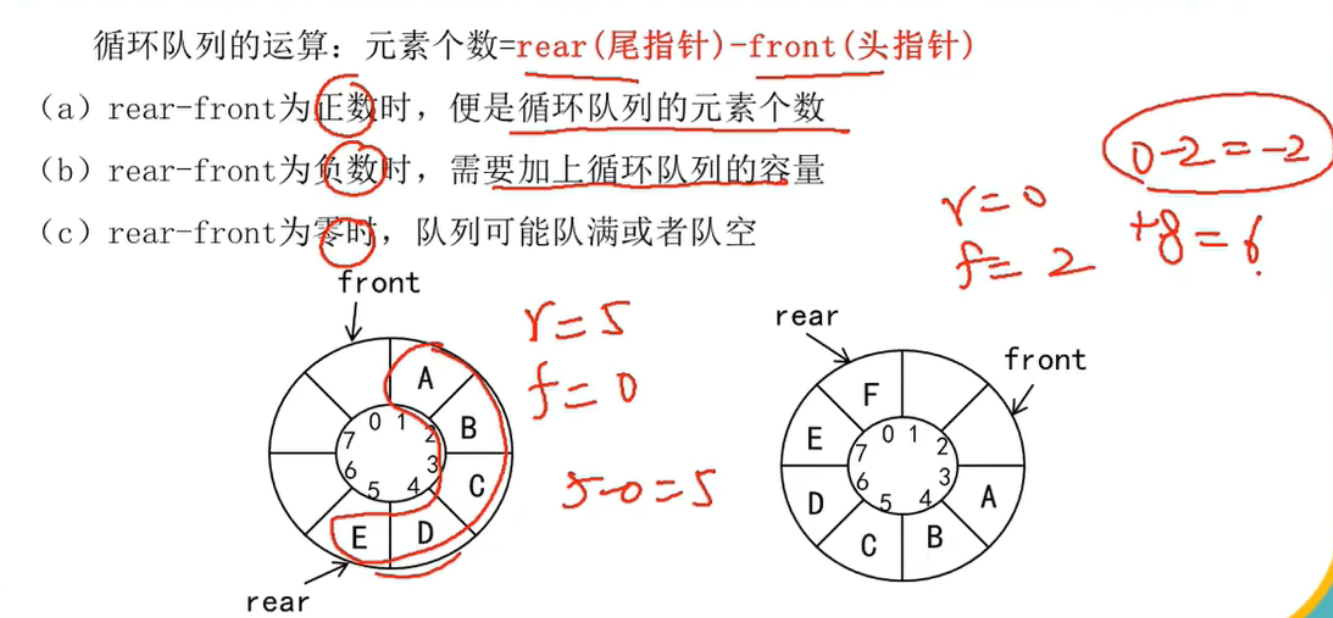
循环队列的“下标运算”是模运算,而不是简单 ++/--。
新下标 = (旧下标 – 1 + MAX) % MAX // 退队
新下标 = (旧下标 + 1) % MAX // 入队
1. 环境复位
-
容量 MAX = 100,下标 1~100 对应数组 0~99 即可,模 100 处理。
-
初始:front = rear = 100(即数组位置 99)
-
目标:front = rear = 50(即数组位置 49)
-
约束:整个过程中不能出现 size=100,否则会被当成“满”而阻塞插入;
但size=0 随时可插入,因此最简单路径就是“只插不退”或“插退相等”。 -
2. 一条可行的“空转”路径
(用数组 0-base 写,看得更清楚)步骤 操作 rear(数组下标) front(数组下标) 公式 说明 0 初始 99 99 空 1 入队 (99+1)%100 = 0 99 仍空(因为马上退掉) 2 退队 0 (99+1)%100 = 0 又回到空,且 front/rear 同时前挪 1 … 重复“插入再删除” … … 每轮 front 和 rear 同步 +1 50 经过 50 轮“插-删” 49 49 对应原题下标 50 此时队列里始终 0 个元素,但 front/rear 已经“绕圈”走到 50,
完全符合“若干正常入队退队操作后 front = rear = 50”。
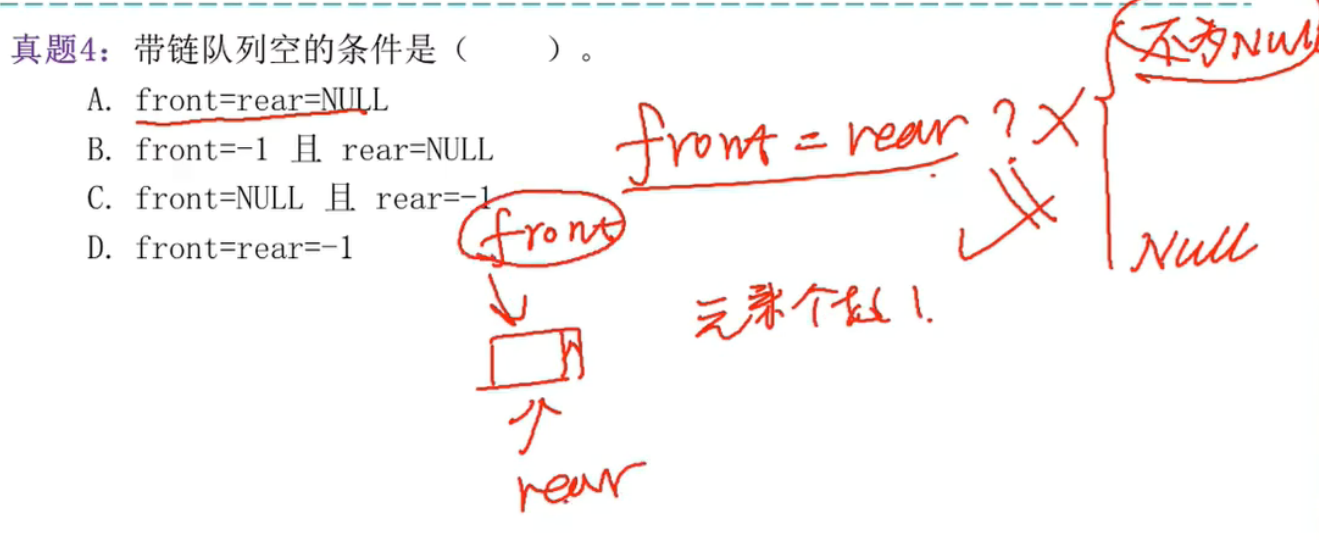
如果front=rear,那么元素可以是1个,也可以是空,因为链式队列定义是front指向头元素,rear指向队尾元素。
栈和队列是“逻辑上的规则”:只定义了 “怎么进出数据”,不管 “数据实际存在哪儿”。逻辑结构只关注数据之间的关系,不关注数据在内存怎么摆设,包括二叉树也是逻辑结构,它们各自定义了一种数据关系的规则,互不依赖,谁也不比谁“底层”。真正实现时,都可以用数组或链表来“落地”
线性表、树、图、栈、队列
顺序表(数组)、链表、散列表、顺序栈、链栈…
在链式队列里,front == rear 只可能有两种情况:
要么队列为空(都指向 NULL),
要么队列里只有一个节点(都指向它)。
@_java_python:
• 只在栈顶操作(插入/删除),所以只需要一个 top 指针。
• 每个节点通过 next 指向下一个节点,形成一条单向链表。
链队列:
• 在队尾插入,队头删除,所以需要:
◦ front 指向队头节点(用于删除)
◦ rear 指向队尾节点(用于插入)
• 每个节点仍然有 next 指针,用来链接下一个节点。

✅ 总结一句话:
链栈和链队列的节点结构完全一样,都有 next 指针;区别只在于链队列用了两个指针(front 和 rear)来管理链表的两端,而链栈只用了一个 top 指针。
typedef struct StackNode {
int data;
struct StackNode *next;
} StackNode;
在链式存储结构中,top、front、rear 指针都是直接指向“节点本身”,而不是“节点之前的位置”。
只有**顺序存储结构(数组实现)**中,才可能存在“指针指向元素之前位置”的情况。
数组里的元素永不释放,只做覆盖或移动下标。
◦ 顺序栈常用的“top 指向待插入位”(即栈顶元素之后)时,入栈直接写 stack[top++],出栈只需 top--,不需要保存任何地址。
链式必须保存“可 free 的真实地址”,因此指针只能落在节点本身;顺序只是移动逻辑下标,从不真正销毁元素,所以可以让指针停在“前一个”或“后一个”位置以换取代码简洁或空满判别。
◦ 循环队列为了区分“空”和“满”,往往让
• front 指向当前队头元素
• rear 指向下一次插入位置(即队尾元素之后)
这样“空”条件就是 front == rear,“满”条件变成 (rear+1)%MAX == front,牺牲一个单元即可区分,逻辑简洁。
因为元素只是被“标记为无效”而不会被 free,所以下标完全可以跑到“元素之前”或“元素之后” 的位置,没有任何内存风险。
