






python出错
0



最佳答案
0
可以发一下错误代码和完整代码吗?
收获园豆:50
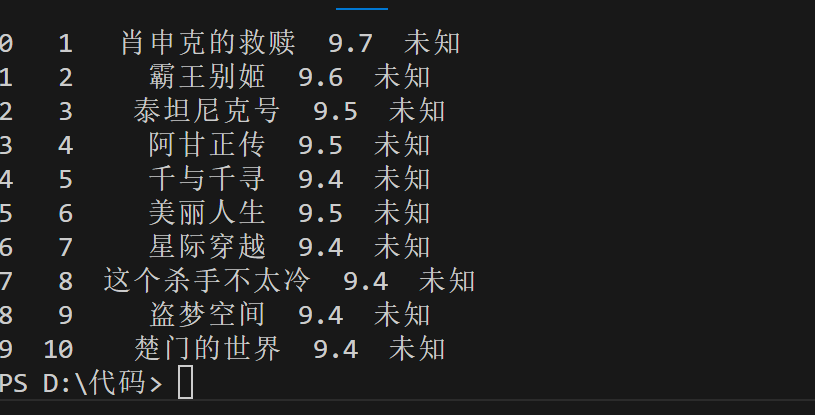
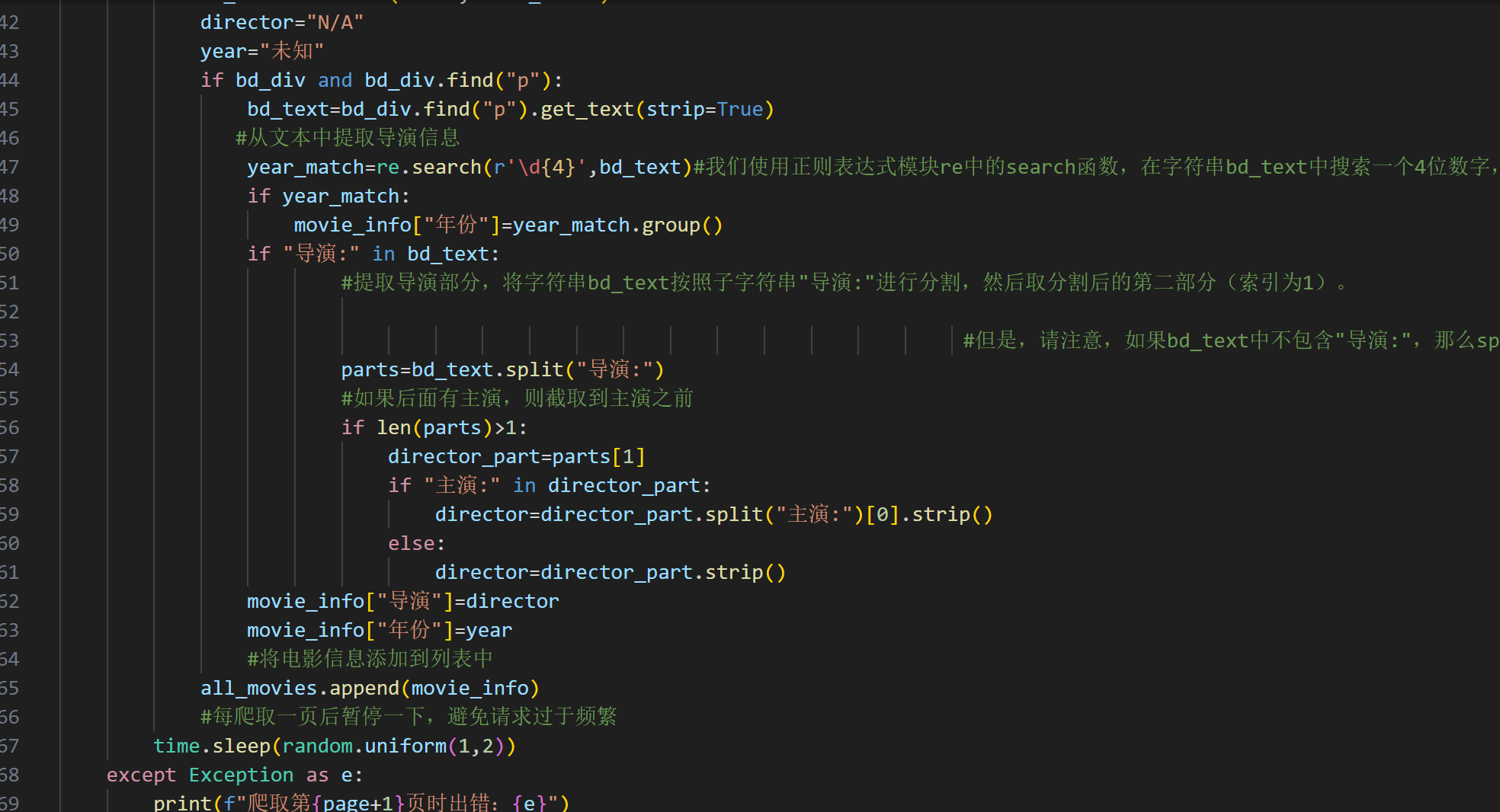
这个样子,哥
@明月落松下: 你这样给我看感觉也没问题啊。不是能运行吗?你是不是想说那个输出年份显示未知?我们也不知道,你需要给我们看一下你这个bd_text的格式
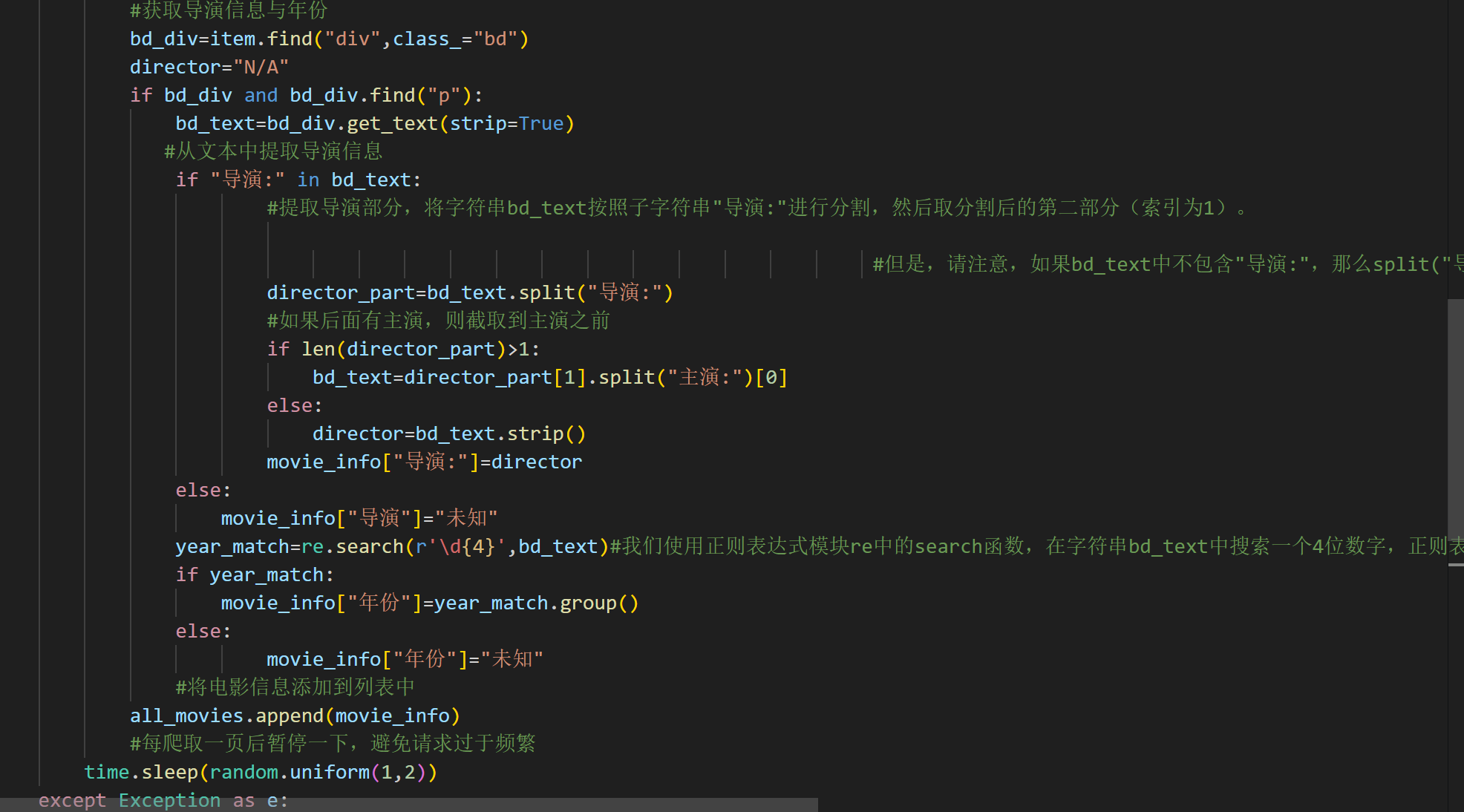
是这样的,哥。我的射向是年份也能够被捞出来,但不知道是我层级出错了,全是未知。我改了几版,越高越错
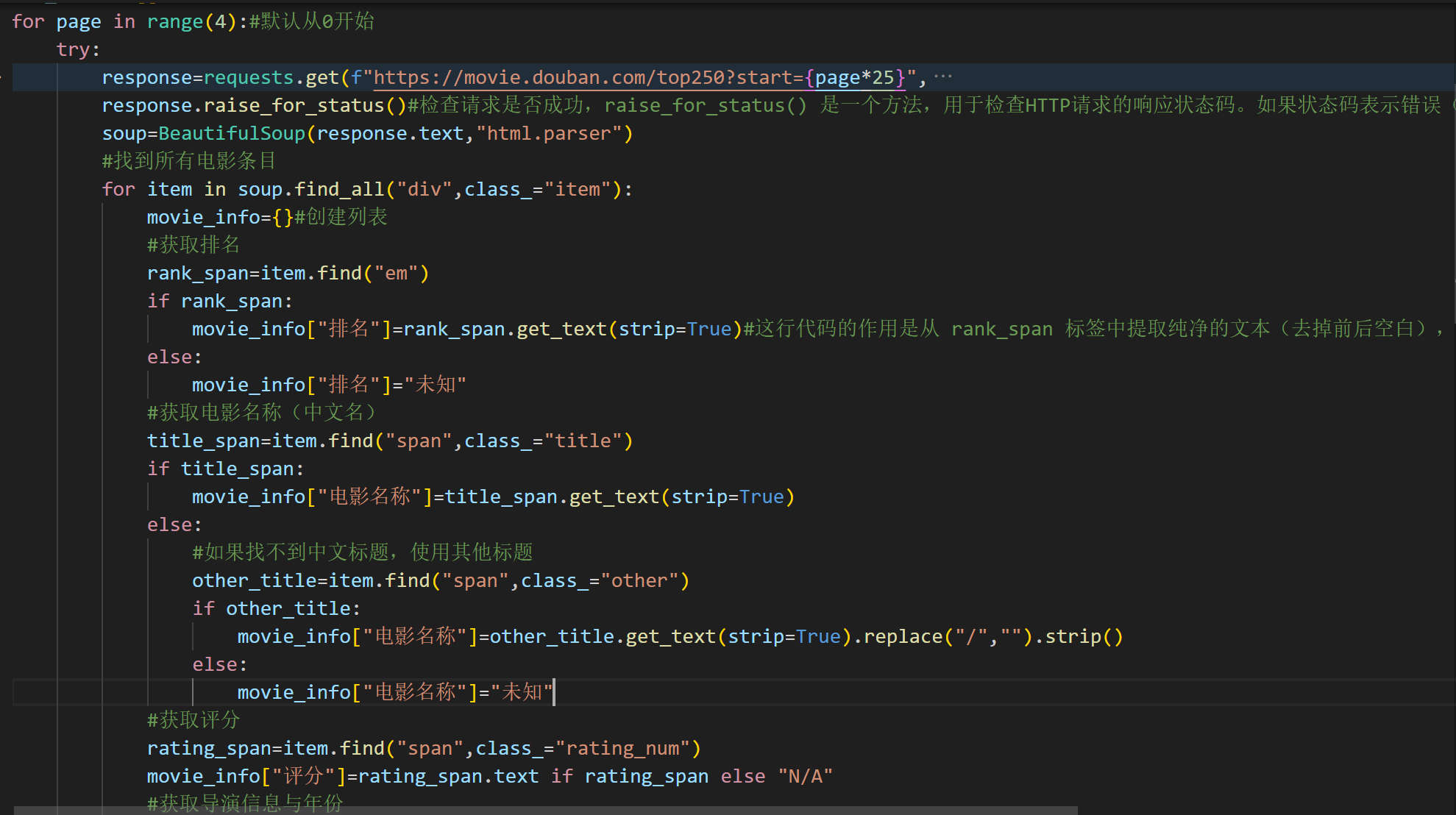
@明月落松下: 对于你一开始你找的'\d{4}',代码没找到你想要的年份导致输出或啥的直接赋值为未知。
对于你最新的代码我稍微增添了一部分在最下面的代码,现在可以提取年份了
from bs4 import BeautifulSoup
import re
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Referer": "https://movie.douban.com/top250"
}
response = requests.get(f"https://movie.douban.com/top250?start={0*25}",headers=headers)
response.raise_for_status() # 检查请求是否成功,raise_for_status() 是一个方法,用于检查HTTP请求的响应状态码。如果状...
soup = BeautifulSoup(response.text, "html.parser")
# 找到所有电影条目
for item in soup.find_all("div", class_="item"):
movie_info = {} # 创建列表
# 获取排名
rank_span = item.find("em")
if rank_span:
movie_info["排名"] = rank_span.get_text(strip=True) # 这行代码的作用是从 rank_span 标签中提取纯净的文本(去...
else:
movie_info["排名"] = "未知"
# 获取电影名称(中文名)
title_span = item.find("span", class_="title")
if title_span:
movie_info["电影名称"] = title_span.get_text(strip=True)
else:
# 如果找不到中文标题,使用其他标题
other_title = item.find("span", class_="other")
if other_title:
movie_info["电影名称"] = other_title.get_text(strip=True).replace("/", "").strip()
else:
movie_info["电影名称"] = "未知"
# 获取评分
rating_span = item.find("span", class_="rating_num")
movie_info["评分"] = rating_span.text if rating_span else "N/A"
year_span = item.find("div",class_="bd")
year_match = re.search(r'\d{4}', year_span.get_text())
if year_match:
movie_info["年份"] = year_match.group()
else:
movie_info["年份"] = "未知"
print(movie_info)
quit()@ProJon: 好的,能捞出年份了,谢谢哥
