






大神在哪里啊大神在哪里?SQLServer2008查询效率!
0

我有一张表,共有56个字段。发现以下情况:
1、我在我的开发机执行sql语句
set statistics time on
SELECT * FROM [eShop].[dbo].[Product]

(多次执行,时间平均在90-100ms)
2、在服务器上有相同的数据库,相同的表,相同的内容。执行同样SQL语句,执行结果为:
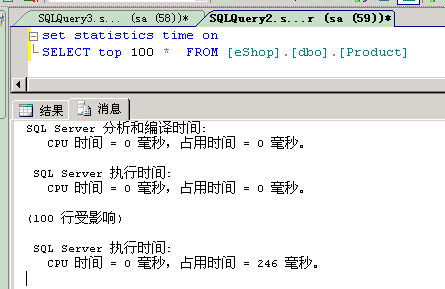
(多次执行,时间平均在250ms)
3、在我的开发机连服务器的数据库,执行该语句,执行结果为:
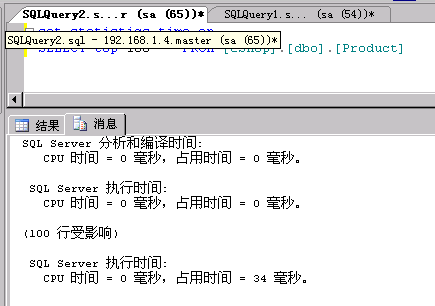
(多次执行,平均时间只有35ms左右)
以上是现象。
问题是:同样的数据库,同样的表,同样的内容,同样的系统(server 2003),服务器的硬件也并不比我的开发机差,不知道为什么执行时间差这么多?
而在硬件比较差的另一台服务器上用sqlserver2000的数据库查询速度反而更快。不知道是什么原因?有人碰到过吗?
问题补充:
数据库版本为sqlserver 2008 R2 ,补丁为sp2。
已经在多台服务器上做过测试,执行时间从七八十毫秒到五六百毫秒不等(有的硬件好的服务器执行时间反而比差的耗时还要长)。
而且就取一百多条数据,怎么会用时这么长呢?sqlserver2005和sqlserver2008 似乎同样有这个问题。而在sqlserver2000上就没有这个问题(不会超过50ms)。

最佳答案
0
set statistics io on
比较一下IO情况
收获园豆:53

现在的问题是 从我的开发机连服务器是最快的(35ms左右), 然后是我的开发机(100ms左右),而直接在服务器上执行却是最慢的。您有试过直接查询一个字段比较多的表用的时间大概是多少么?怎么会这么慢呢?是不是不正常?用sqlserver2000的时候是很快的。已经在好多服务器上试过了,时间都不等,但是都很慢。希望您能帮我看看,找找原因啊!!
@捂汗: 服务器上是SQL Server 2008的Management Studio吗?
@dudu: 嗯 服务器上装的也是同样版本的SQL Server 2008的Management Studio , r2版 , sp2的补丁 系统server2003,
@捂汗: 建议比较一下执行计划
开发机的
服务器的 @dudu:
@dudu:
@捂汗: 能不能请问一下您用sqlserver2008查询一个复杂点的表的话大概多长时间??
@捂汗: 一般都应该控制在100毫秒内
@dudu: 嗯 这个就是开始时发现有个存储过程耗时比较长,然后优化优化到最后 只是这么一个简单的select居然就要这么长时间,但是用sqlserver2000的执行同样的语句就很快。真是搞不清楚为啥了
@dudu: 您的意思是我的 等待时间 太长了? 服务器ip是 192.168.1.4
我在我的开发机上连本机 . 用100ms,连服务器 ip:192.168.1.4 却只要三十几毫秒,反而比直接连本机还快。
而我直接远程到服务器上在服务器上执行反而是最慢的。
@捂汗: “直接远程到服务器上在服务器上执行”,这时你在Management Studio中是通过哪个IP地址连接的(服务器名称填的是什么?)
@dudu: 现在写的是 . ,我试过直接写ip 192.168.1.4 也是一样的
@捂汗: 一样的慢
@捂汗:服务器的缓存可能有问题,检查程序占用的内存情况,然后去看看虚拟内存。
@捂汗: 用127.0.0.1连接试试
@dudu: 用127.0.0.1连后出现了55ms 第二次100多ms 然后以后就 100多ms 300多ms的没准了
@dudu: 我可以把数据库发给您,您在你那儿试一下嘛?或者您自己有类似的表测试一下时间?=_=!!
@捂汗: 服务器上有没有装防病毒软件?
@dudu: 嗯?什么意思?这个库是测试用的不是正式的数据库,服务器也是测试服务器。没有装防病毒软件,这有关系吗?
@捂汗: 那把数据库发过来吧,邮箱见站内短消息
@捂汗: 用你的数据库测试了一下,你的表中有这么多字段,SELECT *需要100多ms是正常现象,唯一的解决方法是减少SELECT的字段数,比如:
SELECT TOP 100 [ProductID] ,[ProductCode] ,[PartnerID] ,[TrademarkID] ,[ProductName] ,[Introduction1] ,[Weight] ,[Size] ,[PackageSize] ,[MediaUrl] ,[MediaPic] ,[Price] FROM [eShop].[dbo].[Product]
执行情况:

@dudu: 但是同样的库用sqlserver2000 就很快啊
@捂汗: 是同样配置的机器吗?我这边用SQL Server 2012也是同样的问题
@dudu: 我select前10条 就0毫秒
但是select 11条以上 就瞬间提升到80 毫秒 ,这样也正常吗??
就瞬间提升到80 毫秒 ,这样也正常吗??
@dudu: SQL server2012也很快是吗??
@dudu: sqlserver2000 在配置更低的服务器上也很快
@捂汗: SQL Server 2012比你的SQL Server 2008还要慢
@捂汗: 找到数据很快,我猜测时间耗在了取数据的IO操作上,硬盘的读取速度会产生直接的影响
@dudu: 会不会是微软对高版本的SQL Server有默认更高的服务器硬件要求?
@捂汗: 这个不清楚
@dudu: 还有个疑问就是为什么在我的开发机连服务器取数据会是最快的呢?
@捂汗: 这个我没研究过,如果真是这样的,是好事情,因为一般部署时应用程序也是放在另外的服务器上
@dudu: 应该是management显示数据的缘故,不同版本在显示数据的时候有区别,你查询5个字段,然后比较2000和2008。
@kylin.chen: 我这边没有SQL Server 2000的环境
@kylin.chen: 在profile里的时间应该和显示数据没关系吧?
按理应该没有关系,我看你本地机查询时读次数是256,怎么服务器是258次。
其他回答(9)
0
应该是数据取回来在management里显示的时间过长,你看server profiler里的执行情况。
收获园豆:15
我的开发机
服务器 
0
硬件一样,不代表全部硬件都用来跑数据库啊~~正式服务器估计还有别的事情做~
经常需要这问题~不是太慢的话,就不去管它~
收获园豆:5
我感觉我的开发机比服务器做的 别的事情还要多呢
@捂汗: 从你发的图,感觉服务器上的读次数要多很多啊?
@幻天芒: 我发的图?现在这个数据库闲着呢,都是我手动执行的
0
拿豆豆来的
收获园豆:1
=_=!帮忙看看问题噻
0
开发机连服务器的数据库操作时间时最短的?围观大神的解答....
收获园豆:5
是啊 ,费解的很啊,大神快来吧
0
围观大神来解释。
收获园豆:1
0
围观大神解答 不过 数据量大于100万时候 select * 还是不要的好
收获园豆:5
代码里当然不会这么写了,只是发现这个问题,就这么抛出来了而已
0
索引碎片吧?
服务器上数据乱的,而你本机和开发机上数据可能是从服务器上copy来的,所以是顺序的,自然查询快
收获园豆:15
不是,特意整理过磁盘碎片,没用。而且在好多服务器上copy过好多次,虽然时间各有不同,但是都很长
@捂汗: 不是磁盘碎片,是索引碎片。比如理想状况下,1个page上可以放10条记录,100条记录放10个page就可以了。但如果有索引碎片,可能100个page也不够。sql server的物理读取都是以page为单位的,所以无疑,相同的记录数,page越多,读取越慢。
验证方法是把原来的数据表删掉,然后重建,再从其他服务上批量导入数据。注意我说的不是整个数据库的backup/resetore,而是单个表的delete/create。
@捂汗: 使用sys.dm_db_index_physical_stats()动态管理视图分别在本机/开发/服务器上查询一下索引碎片状态。如果我猜测没错,服务器上的索引碎片应该不小。
0
解决啦,哈哈哈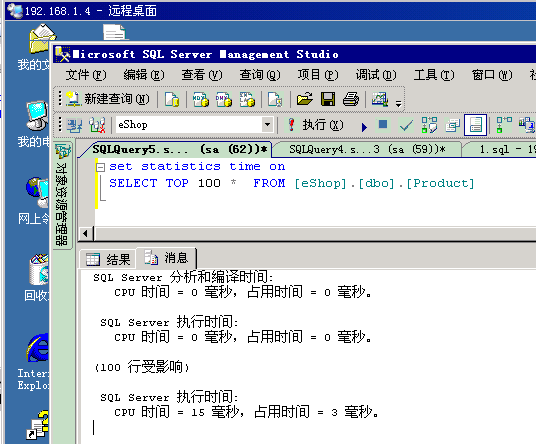
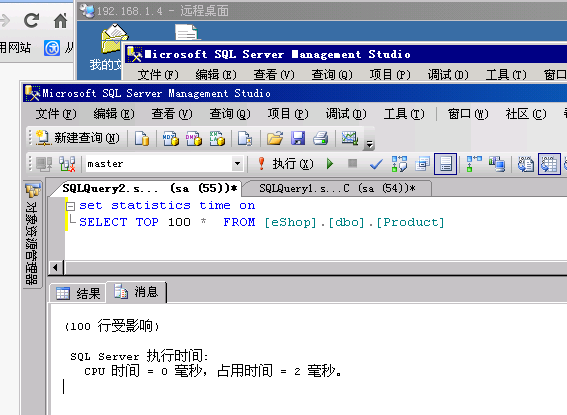
自己好的?
@kylin.chen: 不是 ,是改了ssms的网络数据包的大小
0
楼主不地道啊,解决了也不详细说明下。
是SqlServer management studio的问题,有个更改改了ssms的网络数据包的设置,把那个数值调一下就好了,用程序读速度是没问题的
