






[求助] 利用"表达式树"缓存反射出来泛型方法,通过缓存执行后,遇到些性能问题。
0

使用反射调用方法时,在性能上有所损失,通过使用“表达式树”来作缓存,以减少性能的损失。
缓存代码如下:


通过上面的缓存可得到如下结果:

看起来,有点效果。不知道泛型方法能行么?来个简单的试验,对第一张图的代码简单修改了下如下:
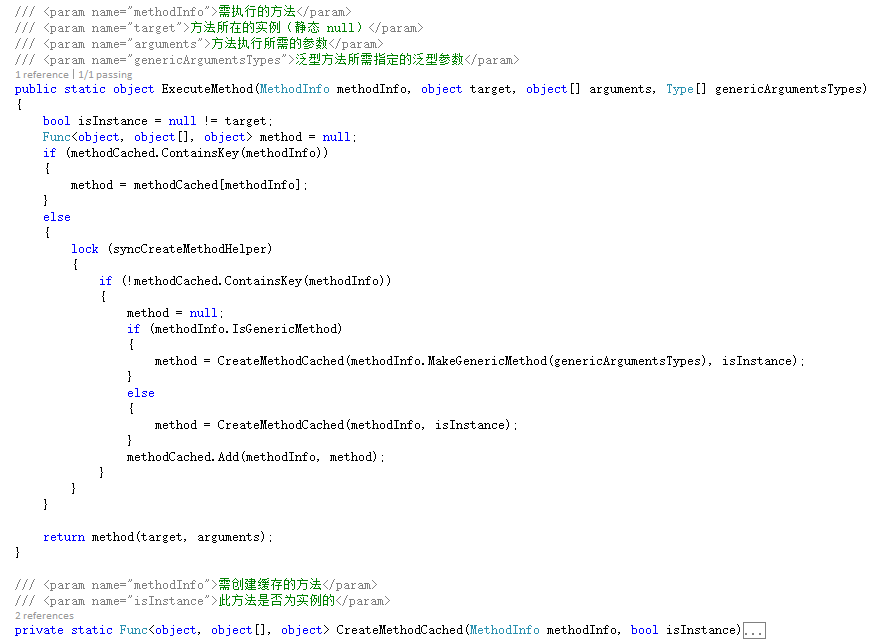
再次看看执行效果:

看起来,还有什么点效果,上面只是简单的试验,只能默认缓存第一次遇到泛型参数,当再次通过其它类型的泛型参数来调用时,会有异常的,带着些许的兴奋,完善下代码(去掉了同步处理),结果悲惧来了...

看下执行结果。

我去,这回比直接调用还耗时,我只是添加了个字典,通过 Key 来获取实际缓存的泛型方法。(针对特定类型的)
这是我所遇到的问题,有些想不通了,请朋友们帮助看看,给个指示..谢谢。

最佳答案
0
这个没去实验,很难给你有效的分析。
1、把dictionary继续使用一级字典而不是二级字典,把泛型函数参数化后的函数作为字典索引,这样是否会提高效率?
2、字典检索也是需要消耗资源的,而你的泛型参数集合生成hash值也是需要时间的,这个时间是否超出了泛型函数反射执行的时间?
3、你的二级字典的索引是字符串,我不知道你为什么用这个策略,如果直接用泛型参数做索引键呢?如果对泛型参数的类型数组进行hash后的int做索引键呢?你用字符串(应该是泛类型参数的序列组合字符串吧)做索引键,估计很消耗时间的。
收获园豆:50
谢谢您的帮助,
1. 这个字典是比较耗时,由其还是带二级的。
2. 泛型参数是个 Type[] ,我仅能想到了把它转换成字符串的形式,以保正唯一性。您提到了 Hash,如果直接在对象上 GetHashCode,即使同内容,但对象不同,也会有不同的结果,如果自己计算 Hash 我仅能想到通过 HashAlgorithm 这个地方,那需要的时间更可怕...
您是通过什么样的方法来减少,反射泛型方法带来的性能损失呢?可否提示一二,谢谢。
@Srouni: 对于泛型函数的反射执行,我还没弄过,不能给你太多的参考,而且,一般而言,我也很少去考虑这个性能(因为目前还没出现因此而导致的性能问题,当然,不代表今后也不考虑这个问题)。
每次new一个array后,它的hash是基于object的,所以这个不便于字典化处理,但是,我
static int GetArrayHashCode(Array array) { int result = 0; foreach(var item in array) { var hash = 0; if(item != null) { hash = item.GetHashCode(); } result <<= 1; result ^= hash; } result <<= 1; result ^= array.Length.GetHashCode(); return result; }
们换个方式来生成字典呢?比如以下的参考代码:
@519740105:
谢谢,您在 GetHashCode 方面的提醒,我之前的测试(针对字典损耗),是不对的(没有用实际的字典,只是简单的模拟个相同的字典结构)。
我的问题确实不在于缓存上,而是在于字典的处理上。
来张结果图吧:

