







sql查询性能低下
0


With ZBS AS( select zb.ZUser_RefererUrl as RefererUrl,zb.ZUser_Id as ID, zb.ZUser_Key as UserKey,zb.ZUser_SousuoKeyword as SousuoKeyword,zb.ZUser_BMobile as BMobile,zb.ZUser_Mobile as Mobile, zb.ZUser_Email as Email,zb.ZUser_Int1 as QQ,zb.ZUser_Str1 as UserPUK,zb.ZUser_Nickname as Nickname,zb.ZUser_StayTotalSecs as StayTotalSecs,ZUser_AddTime as AddTime from ZbsUserInfo as zb where ZUser_AddTime between '2015/10/14 0:00:00' and '2015/10/15 23:59:59' and zb.ZUser_StayTotalSecs>=-1 and zb.Sp_Id in ( 1,2,3,4,5,6,7,8,9,-1) and zb.ZUser_Int1 >0 ) select * from ( select ROW_NUMBER() OVER (ORDER BY AddTime desc ) as ZS,Count(*) over() as Total,* from ZBS where ID in (select min(ID) from ZBS group by UserKey having count(UserKey )>=1 ) ) as T where ZS between 1 and 30
ZbsUserInfo 这个表的数据量有几十万..然后放在数据库查询的时候需要几十秒.
.单表查询性能都这么地下.欲哭无泪..导致web服务器都奔溃.搜了sql性能化相关资料发现大多都是尽量使用索引查询不要使sql语句导致全表查询.本人才疏学浅.特此来寻求优化解决方法.或者其他解决方法.



最佳答案
1
1. in语句影响性能,换成别的试试.
2. 尽量避免在where子句中对字段进行函数操作,否则将导致全表扫描。
3. 建议你分段执行看看到底哪一段代码耗时多.
例如With 那一块执行一次. 然后Select 那一段执行一次. 看看具体耗时比较长的是在哪一段.
然后再慢慢排查是因为哪个where条件导致时间变长.
收获园豆:50
in是权限.这里是按1-9.有时候不确定的权限所以不能>/</between and来解决。where中使用聚合这里是单列去重复..有这样的需求..第三个我试试.
@Kerwin1202:
我觉得你的1-9可以试下换成表变量存起来
DECLARE @News Table ( id int NOT NULL ) INSERT @News ( id ) VALUES (1),(2),(3),(4),(5),(6)
然后in语句换成exists语句
and EXISTS ( SELECT 1 FROM @News WHERE id=zb.Sp_Id)
select zb.ZUser_RefererUrl as RefererUrl,zb.ZUser_Id as ID, zb.ZUser_Key as UserKey,zb.ZUser_SousuoKeyword as SousuoKeyword,zb.ZUser_BMobile as BMobile,zb.ZUser_Mobile as Mobile, zb.ZUser_Email as Email,zb.ZUser_Int1 as QQ,zb.ZUser_Str1 as UserPUK,zb.ZUser_Nickname as Nickname,zb.ZUser_StayTotalSecs as StayTotalSecs,ZUser_AddTime as AddTime from ZbsUserInfo as zb where ZUser_AddTime between '2015/7/15 0:00:00' and '2015/10/16 0:00:00' and zb.ZUser_StayTotalSecs>=-1 and zb.Sp_Id in ( 1,2,3,4,5,6,9,10,11,12,13,14,45,55)
DECLARE @News Table ( id int NOT NULL ) INSERT @News ( id ) VALUES (1),(2),(3),(4),(5),(6),(55),(9),(10),(11),(12),(14),(45); select zb.ZUser_RefererUrl as RefererUrl,zb.ZUser_Id as ID, zb.ZUser_Key as UserKey,zb.ZUser_SousuoKeyword as SousuoKeyword,zb.ZUser_BMobile as BMobile,zb.ZUser_Mobile as Mobile, zb.ZUser_Email as Email,zb.ZUser_Int1 as QQ,zb.ZUser_Str1 as UserPUK,zb.ZUser_Nickname as Nickname,zb.ZUser_StayTotalSecs as StayTotalSecs,ZUser_AddTime as AddTime from ZbsUserInfo as zb where ZUser_AddTime between '2015/7/15 0:00:00' and '2015/10/16 0:00:00' and zb.ZUser_StayTotalSecs>=-1 and EXISTS ( SELECT 1 FROM @News WHERE id=zb.Sp_Id)
有时还比临时表快上那么几十毫秒.用in好像会重用缓存数据.而临时表好像每次查询时间都是这么多+-20浮动..直接in有时小有时大
@李丶GuanYao: 我试了试,我用SQL Server profile这个查看了发现用临时表查询和in如果相同数量.查询时间都想差不多

@Kerwin1202:
你分段执行的时候. 是哪一块消耗时间比较多呢..
检查一下你这几个字段哪个没加索引.. ZUser_AddTime,ZUser_StayTotalSecs,ZUser_Int1
@李丶GuanYao:
select count(*) from sys.indexes where name='ZUser_Int1';
这样看了看貌似一个索引都没有
@李丶GuanYao:
CREATE NONCLUSTERED INDEX IX_TEST_TNAME ON GoldResources(ZUser_Int1) WITH FILLFACTOR = 30 GO
消息 1088,级别 16,状态 12,第 2 行 找不到对象 "ZUser_Int1",因为它不存在或者您没有所需的权限。
创建索引就这样了...
@Kerwin1202:
你查询索引的方式有点问题. name应该是索引名,. 而不是字段名.
感觉你创建索引好像也有点问题. 你的ZUser_Int1等字段不是在你的ZbsUserInfo表里吗?. 怎么你创建索引的时候用的是GoldResources?.
@李丶GuanYao: GoldResources是打错了.打成数据库了.后来改了.
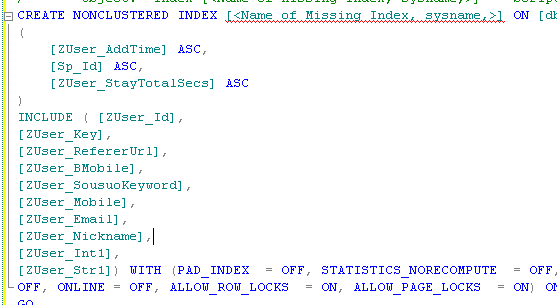
已经有这样的 索引..
其他回答(3)
1
1、建索引原则,一般根据所查询的条件或关联的条件来建,如ZbsUserInfo:
ZUser_AddTime,ZUser_StayTotalSecs,Sp_Id,ZUser_Int1 这些列
可能会是这样子的
CREATE NONCLUSTERED INDEX [索引名] ON [dbo].[ZbsUserInfo]
(
ZUser_AddTime,
ZUser_StayTotalSecs,
Sp_Id,
ZUser_Int1
)
INCLUDE (
ZUser_RefererUrl,
ZUser_Id,
ZUser_Key,
ZUser_SousuoKeyword,
ZUser_BMobile,
ZUser_Mobile,
........
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
这种手动建索引。
2、如果你使用的是MsSql2008及以上的版本就更好办了MSSMS提供了一个方案自动提示你要建什么索引非常方便
查询->包括实际的执行计划,点击一下就执行你人慢SQL语句吧
下面为:结果、消息、执行计划
答案就是执行计划中会显示为“缺少索引(...”右键-》缺少索引详细信息
收获园豆:30
这个之前创建了.采用的你说的第二种方法创建的.
0
试试用SQL Server profile看看具体哪里是性能瓶颈,然后再优化
0
1.索引,
我建议
create index ix_x on zbs(Zuse_int1,zuser_stayTotalSecs)
create clusted index ix_y on zbs(zuser_addtime) 这里应该你本来就有索引吧。时间这个条件是最常有的。而且数据插入肯定时间顺序一致。
说明一点,1楼的include把所有列都写进来,我不知道他理解到include的意思没有,如果所有都include上来那你还不如不建,有何意思,直接按你的建个聚集索引不就ok了。列数大的索引建起来肯定也慢。
2.in那个地方是可以改写的,这里还应该直接放入上面zbs的条件当中.
我表中2,30个字段..这里读取不是所有列,其中一部分
in我正按照2楼所说的试一试...

