






大文本文件正则匹配的效率问题
0

大文本文件 主要是日志文件,现在需要把日志文件中的内容匹配出来分析,测试显示匹配的耗时非常低,但是不知道为什么访问或者遍历结果集中,却非常慢。
使用多线程处理 效率也没进行很大的变化,还有使用大量数据的时候使用DataTable好还是List存储好~~
测试如图:
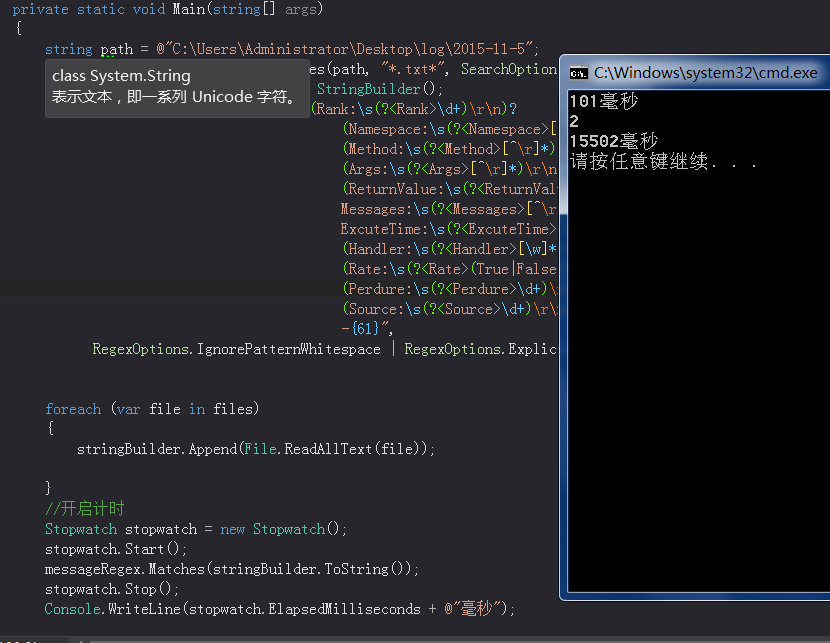


所有回答(2)
0
大文件只能用流处理。
0
使用shell中已有的grep组合一下即可用,windows下有cygwin
如果要自己写代码,可以参考grep的源代码
