







规律性字符串处理,如何校验规律性字符串?如果用正则该如何校验?
0

例:Text\tText\tText\r\n
上面是一个整体,文件里面保存的有N多个。
怎样校验文本中的整体数据符合这个格式?

所有回答(3)
1
能把你的需求说清楚一点么 只过滤其中整数?
不是过滤。
整个文本是一个规律性字符串。
比如:aabbccaabbccaabbcc
这是一个规律性的,如果中间突然出现aabbccaabaccaabbccaabbcc
aabacc 红色部分,那么这个文本就是不符合需求的。
@quxian:
我理解你的意思了,那你最后要的是不符合需求的那段字符串对吗?
@xiaoxiao刀: 嗯,是的。
@quxian:
算是一种思路吧 ,你先找到符合规则的正则表达式,把需要匹配的长字符串,分段和该正则表达式匹配,能匹配成功的就从字符串中截取出去,等所有的匹配完后,省下的就是你要的字符串了
@xiaoxiao刀: 现在想不到合适的思路,您有什么好的方法吗?或者用什么技术?
@quxian:
你试下我上面说的方法,可能性能不是很好,但也是一种方法
@xiaoxiao刀: 问个具体的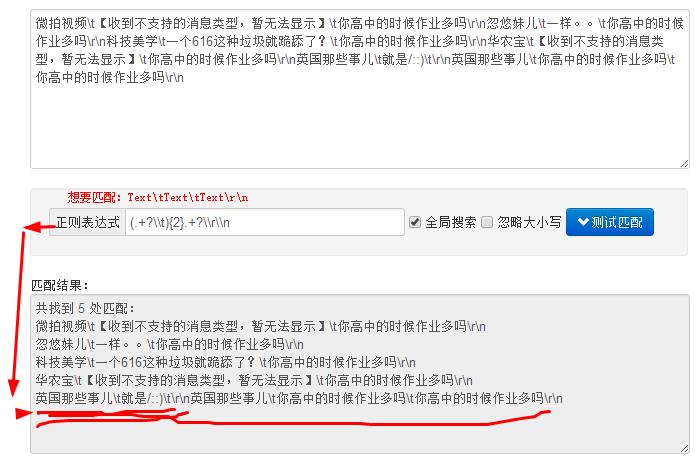
输入数据:
微拍视频\t【收到不支持的消息类型,暂无法显示】\t你高中的时候作业多吗\r\n忽悠妹儿\t一样。。\t你高中的时候作业多吗\r\n科技美学\t一个616这种垃圾就跪舔了?\t你高中的时候作业多吗\r\n华农宝\t【收到不支持的消息类型,暂无法显示】\t你高中的时候作业多吗\r\n英国那些事儿\t就是/::)\t\r\n英国那些事儿\t你高中的时候作业多吗\t你高中的时候作业多吗\r\n
该如何匹配?
@quxian: 感觉你这个是不是不能这样的纯粹用正则判断,你字符不一定是有规律性的,中间有点差错就会不匹配。
@g皓皓: 他的规律仅仅是:Text\tText\tText\r\n
类似这样的,至于每个Text具体是什么,只要Text包含的字符不破环这个规律就行。
也可以说Text不包含[\t|\r\n]就行。
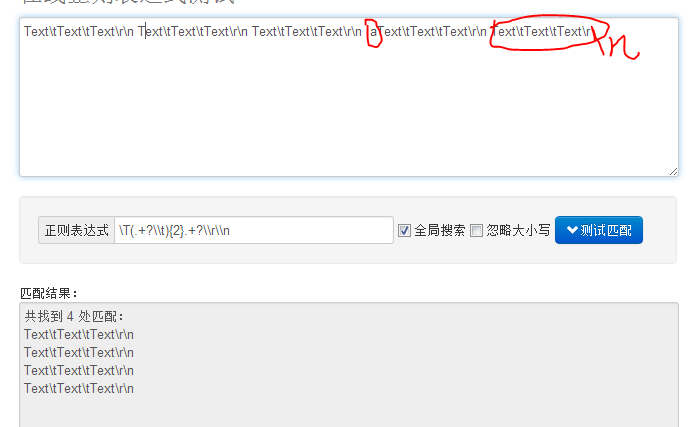
@quxian: 规律:
Text\tText\tText\r\nText\tText\tText\r\nText\tText\tText\r\nText\tText\tText\r\n
@quxian:
如果规律这样的话。前面加个标示符,只匹配这样的(如图)。不知道是不是你想要的?
反正肯定是要能保证规律字符的位数相同。实在不行就单独写判定把
@quxian:
只是举个例子,具体正则表达式你还得改下
比如你的字符串是:
Text\tText\tText\r\nText\tText\tText\r\nText\tText\tText\r1\nText\tText\tText\r\n
首先你用 split("\r\n") 去吧该字符串分为n个元素字符串,然后把每个字符串尾端加上\r\n 除了最后一个元素字符串
你用这个正则表达式去匹配 ^.*\\t.*\\t.*\\r\\n$ 每一个小字符串若返回成功则跳出返回失败则输出该字符串 这个字符串就是你要找的
@xiaoxiao刀: 谢谢了,现在我想的一种方法就是这样,由大化小。分割成小的字符串List,再对每项进行判断。
期待更好的解决方法。
因为我给的例子只是其中一种。
@quxian:
如果是多种情况 用正则表达式的 | 就 ok了呀 也是这个思路 只不过你把每种情况的正则都用 | 分开就行了
0
给点思路吧。
表达式:(\w)\1{2,}
测试结果:
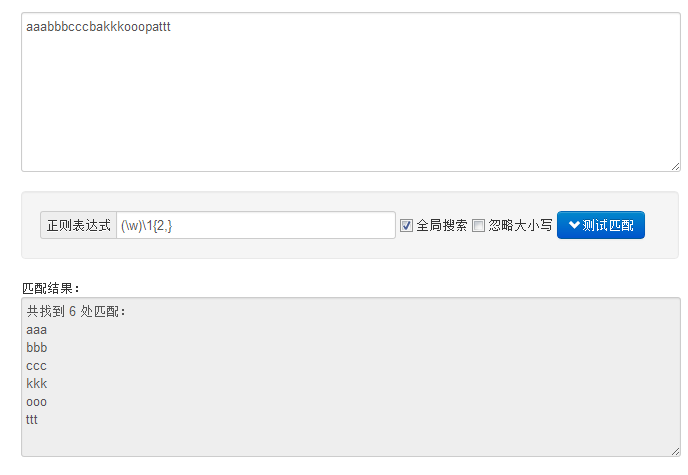
希望能帮到
谢谢! 你看一下上面那个具体的问题,看能不能正确的匹配
0
(.+?)\\t\1\\t\1\\r\\n
微拍视频\t【收到不支持的消息类型,暂无法显示】\t你高中的时候作业多吗\r\n忽悠妹儿\t一样。。\t你高中的时候作业多吗\r\n科技美学\t一个616这种垃圾就跪舔了?\t你高中的时候作业多吗\r\n华农宝\t【收到不支持的消息类型,暂无法显示】\t你高中的时候作业多吗\r\n英国那些事儿\t英国那些事儿\t英国那些事儿\r\n
共找到 1 处匹配:
英国那些事儿\t英国那些事儿\t英国那些事儿\r\n
是这个意思嘛?希望你找个更有代表性而没有那么多冗余的例子来阐述下需求
