






c 语法问题求解释
0
[已解决问题]
解决于 2017-01-11 10:19

小弟是做c#的,因为要开发一个加密锁,需要用到一点c,我写了下面的代码
WORD to_write_file() { WORD errcode; // char encrypt[0x16]="abcdeabcdeabcde0"; // encrypt[13]= InOutBuf[5]; encrypt[14]= InOutBuf[6]; encrypt[15]= InOutBuf[7]; encrypt[16]= InOutBuf[8]; // errcode = write_file(FILE_KEY, 0x0612, 0, 16, encrypt); // memcpy(InOutBuf, encrypt, 16); // return errcode; }
这里的encrypt[13]...根C#中的字符数组下标不一样么,为什么一个长度为16的数组,最后一个下标是16而不是15?这里应该怎么理解?


最佳答案
0
0x16 一般理解为二进制,转换成十进制是22
奖励园豆:5
哦,那也就是说,上面的字符串encrypt定义成[0x10]就行了,因为只存储16位字符,但是下面的,encrypt[16]这里怎么理解,我把上面改成[0x10]了,这样应该就是16位长度,可是下标为什么最后一个是16,难道第一位是1而不是0?
@MSky: c中数组同样是从0开始 ,长度-1结束。代码是你自己写的还是copy的?
@hahanonym: 自己写的,之前这里的13,14,15,16是12,13,14,15,可是测试发现位置不对,改成这样就正好对上了
encrypt[13]= InOutBuf[5]; encrypt[14]= InOutBuf[6]; encrypt[15]= InOutBuf[7]; encrypt[16]= InOutBuf[8];
这是一个16位的密钥,替换了后四位的值
@MSky: 你定义成0x10,然后索引16下标没报错吗?
@hahanonym: 事实就是这样,千真万确。。。
@hahanonym:
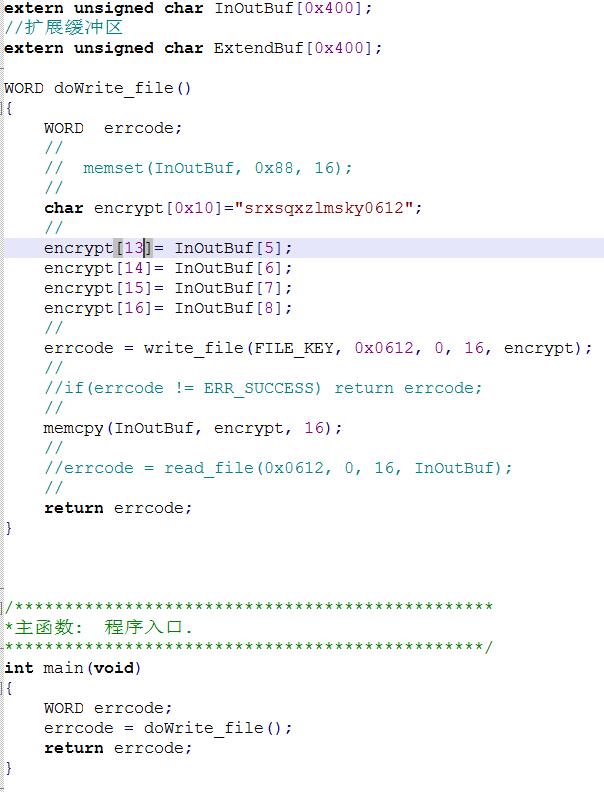
这是代码,这段代码在加密锁内运行,首先通过用户api向锁的输入输出缓冲区输入了8个字符,如当前日期(20170111),我在锁内定义了char[0x10],这个16位的字符数组,并给了初始值,然后将输输出缓冲区中的,5,6,7,8四个字符替换到我定义的encrypt的后四位,下图是过程
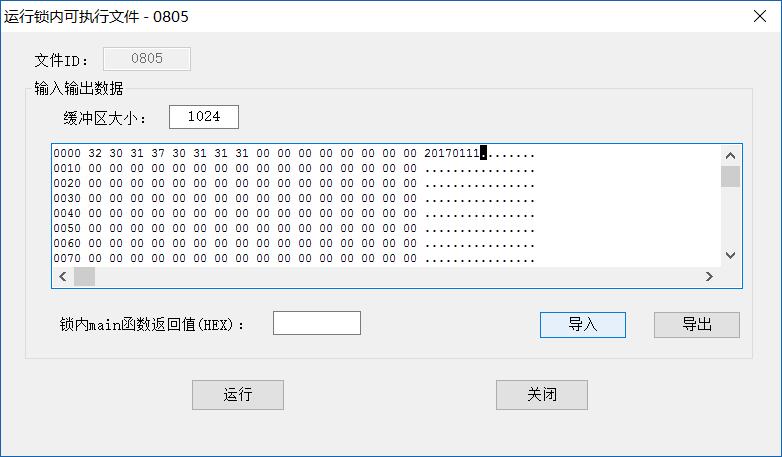
首先我通过输入输出缓冲区,输入了8位日期字符20170111,然后点击运行
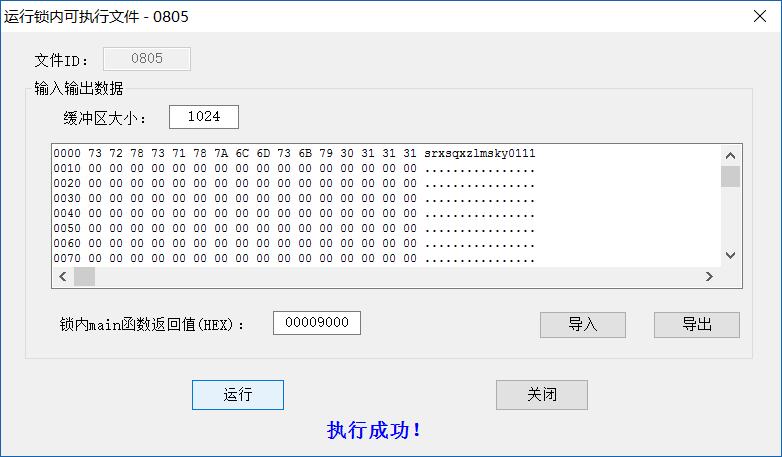
返回的结果正确,将0111,替换到了我锁内预定义的16位字符数组的后4位,这里的所有的数组下标,感觉都是从1开始的,说明书中说锁内使用C语言开发,用的工具是Keil uVision4,真是太诡异了
@MSky: 首先这样定义是报错的 char en[0x10] = "abcdeabcdeabcde0";
其次参考这个文章http://blog.csdn.net/sjtu_huang/article/details/6533140
@hahanonym: 这种写法也是我从网上资料中看到,初始化时好像是可以这样写的,但是如果对一个定义过的变量这样赋值就会有问题,我再问问锁的生产厂家吧
@MSky: 报错的是 左边是 char[16] 右边是 char[17]
其他回答(1)
0
同意一楼的
