






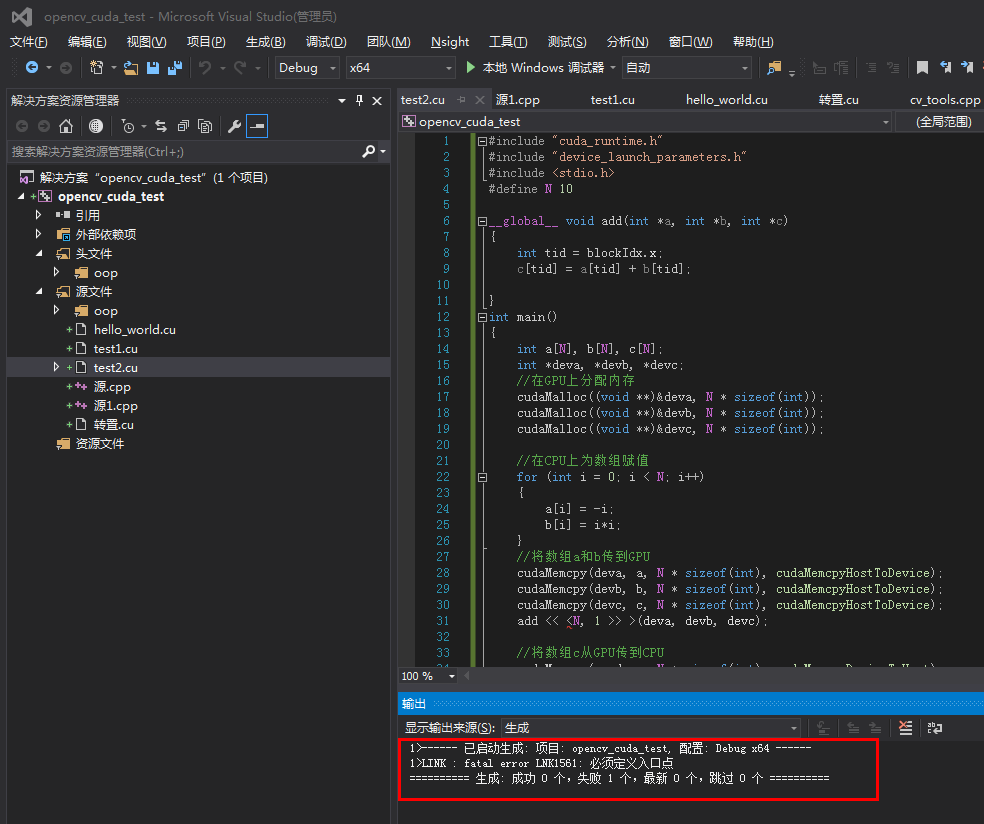
CUDA + VS 编程 出现错误 : LNK1561: 必须定义入口点
0

#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #define N 10 __global__ void add(int *a, int *b, int *c) { int tid = blockIdx.x; c[tid] = a[tid] + b[tid]; } int main() { int a[N], b[N], c[N]; int *deva, *devb, *devc; //在GPU上分配内存 cudaMalloc((void **)&deva, N * sizeof(int)); cudaMalloc((void **)&devb, N * sizeof(int)); cudaMalloc((void **)&devc, N * sizeof(int)); //在CPU上为数组赋值 for (int i = 0; i < N; i++) { a[i] = -i; b[i] = i*i; } //将数组a和b传到GPU cudaMemcpy(deva, a, N * sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(devb, b, N * sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(devc, c, N * sizeof(int), cudaMemcpyHostToDevice); add << <N, 1 >> >(deva, devb, devc); //将数组c从GPU传到CPU cudaMemcpy(c, devc, N * sizeof(int), cudaMemcpyDeviceToHost); for (int i = 0; i < N; i++) { printf("%d+%d=%d\n", a[i], b[i], c[i]); } cudaFree(deva); cudaFree(devb); cudaFree(devc); return 0; }


最佳答案
0
应该是工程问题 新建一个工程 解决了。。
