






大佬来看看这两个sql的区别
0

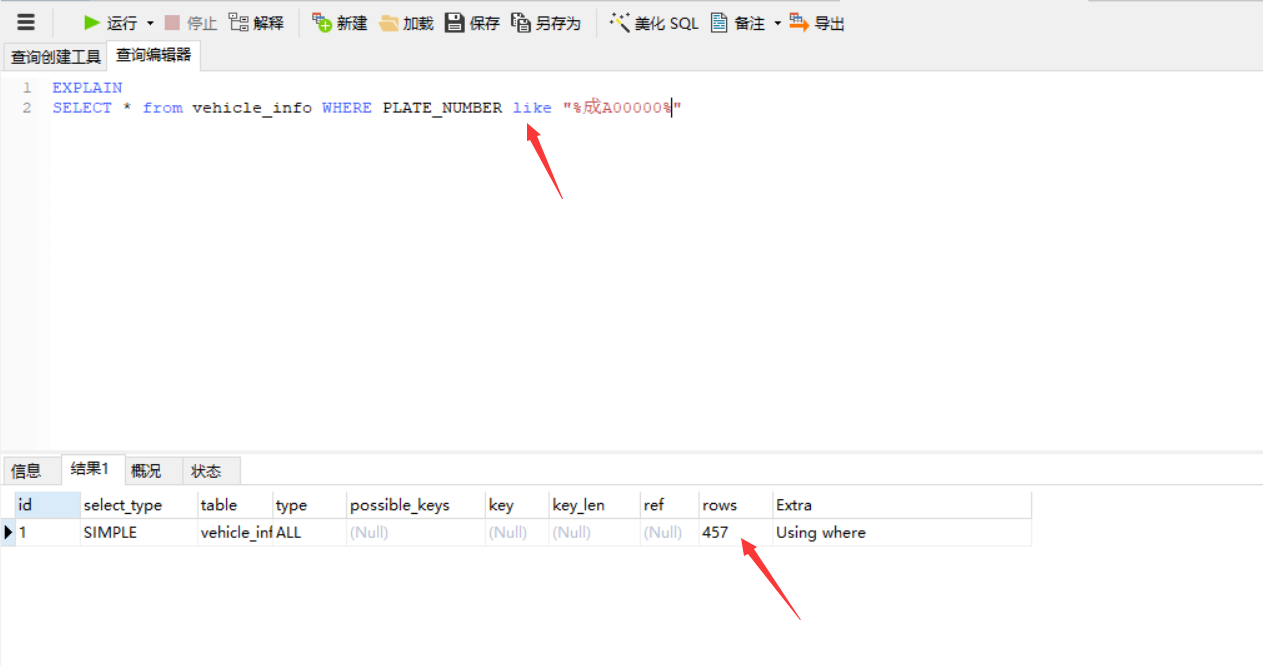
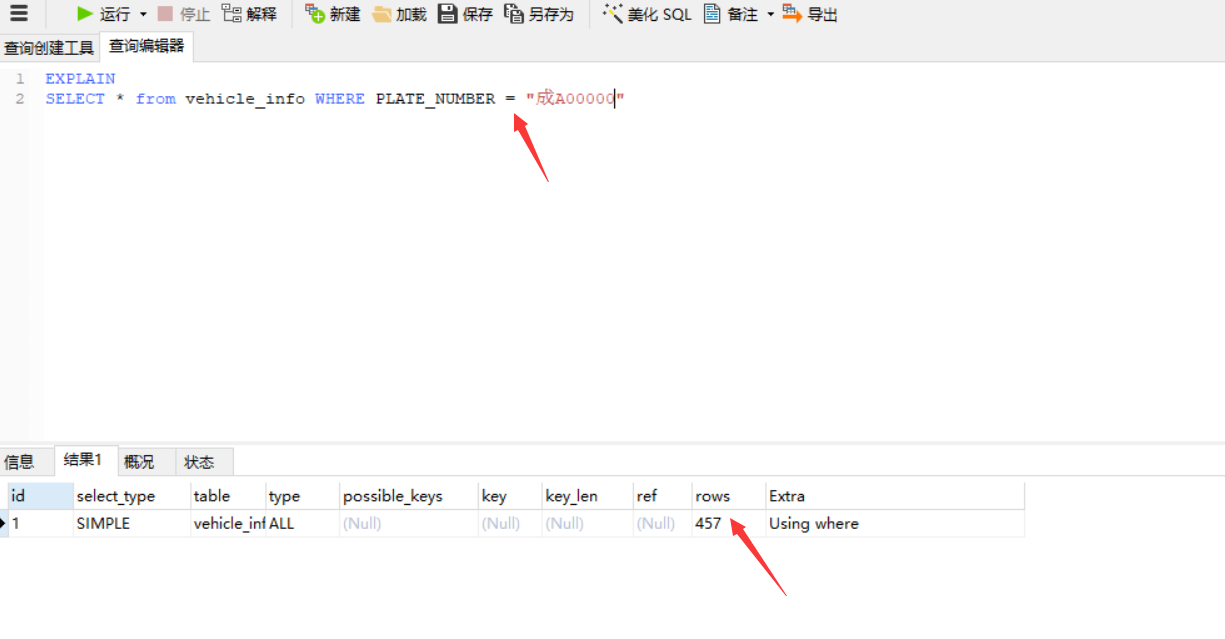

最佳答案
0
都是全表扫描,效率有什么差距?你这个字段也没有索引的吧
收获园豆:10
要有索引才有区别,是吧?
@結城リト: 是的,like只有前面不带%的时候才会用到索引
其他回答(4)
0
LIKE 无法使用索引
0,0。也就是这个字段没建立索引效率都一样,建了就有差别了
0
一个是模糊查找 一个是精确查找 效率当然不一样
但是查询行数都相同呀
0
同样到北京的,为啥高铁和骑自行车到达时间不一样呢?
0
这两个含义都不一样,怎么就比上性能了?一个是全匹配,一个是模糊查询。
