






关于为什么获取不到重定向的最终地址URL的问题?
0

期望实现:通过https://post.alibaba.com/product/posting.htm?catId=138这个请求,获取其重定向后的真实请求地址https://post.alibaba.com/product/publish.htm?catId=126428032
通过谷歌浏览器可以看到操作的请求情况如图:
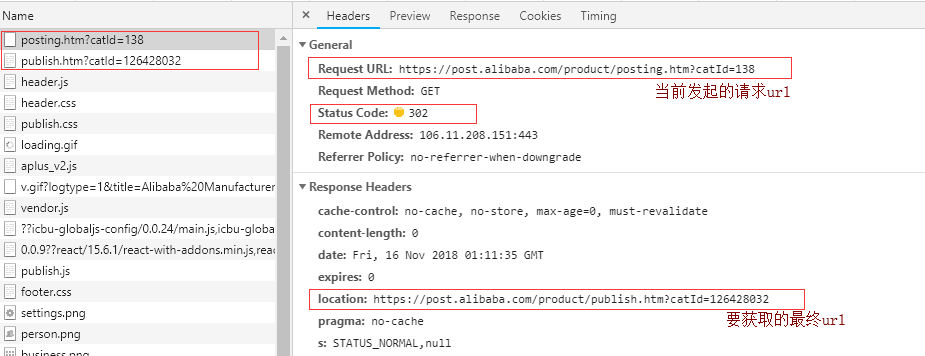
图中可以看到请求的真实url在location中对吧~也就是紧跟在它下面的那个请求~
可是为什么我使用抓包工具和postman发起的请求返回的location都不是最终的真实url反而是我当前请求的原始url呢。。。
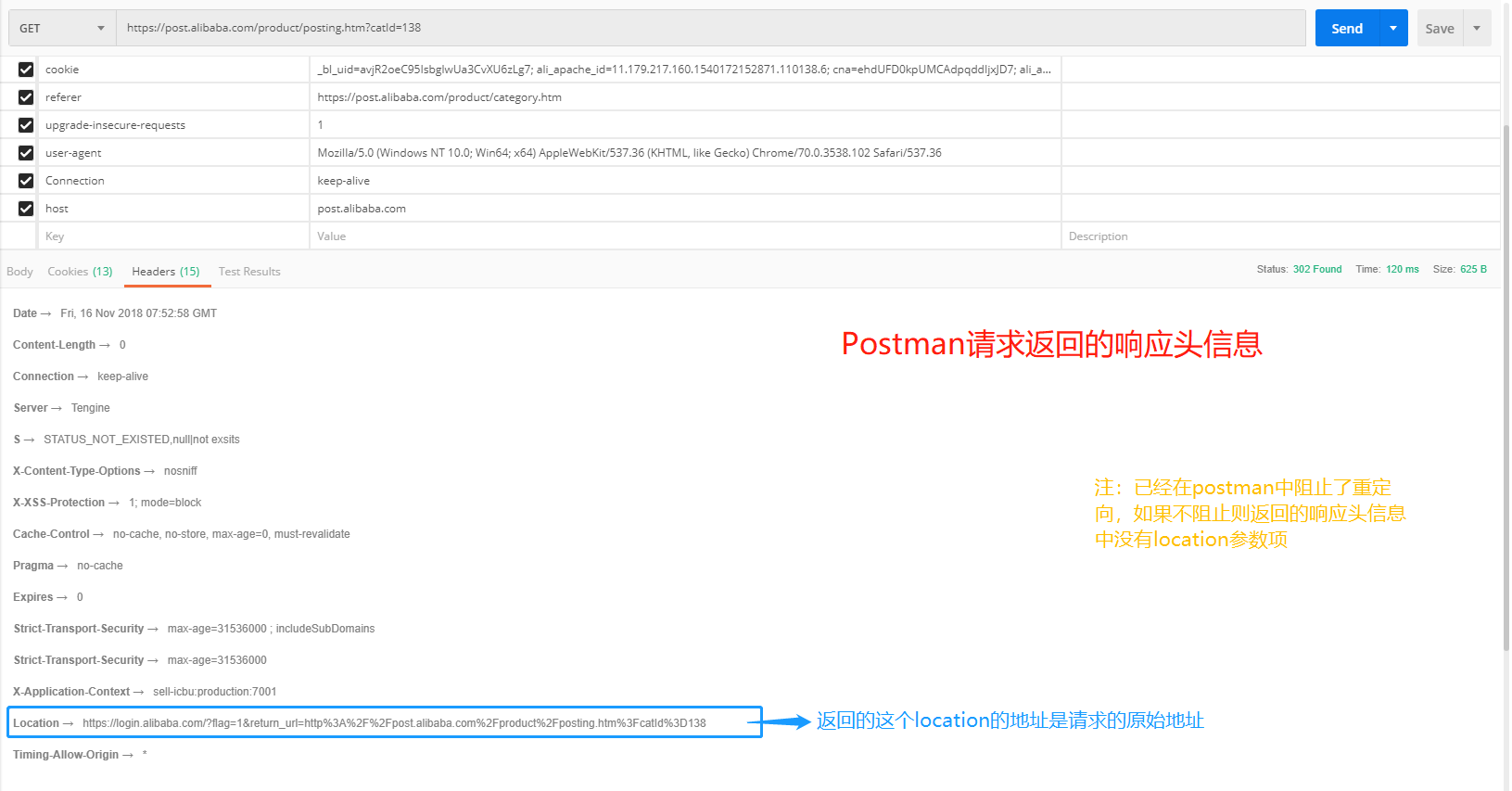
vvv这是用postman请求返回的响应头信息vvv
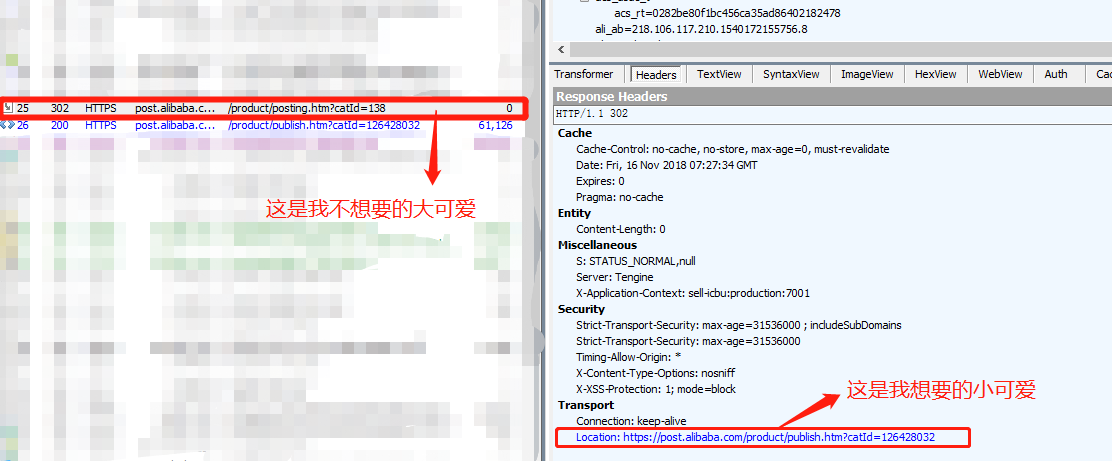
vvv这是用Fiddler抓包工具抓到的请求vvv
用python写了一个很简单的脚本获取到的location也是请求的原始URL:
import requests
from urllib.parse import unquote
cookie = "xxx" #由于此页面有登陆验证,此处cookie包含隐私信息所以省掉了
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7",
"Cookie": cookie,
"referer": "https://post.alibaba.com/product/category.htm",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
"connection": "keep-alive",
"host": "post.alibaba.com"
}
catId = '138'
url = "https://post.alibaba.com/product/posting.htm?catId="+catId
r = requests.head(url, headers=headers, allow_redirects=False)
print(unquote(str(r.headers['location'])))以下是脚本获取到的结果:

注:header请求头参数都与图中浏览器中的是一样儿的~
求大神帮忙给分析一下呗~


最佳答案
1
试试下面的代码
r = requests.head(url, headers=headers, allow_redirects=True)
print(r.url)
收获园豆:70
谢谢你的回答嗷~ 不过这个我尝试了也不行哦 我在网上搜了很多 比如下面这个代码
getHeaders = requests.get(url, headers=headers, allow_redirects=False)
print(unquote(str(getHeaders.headers['location'])))一直都是返回的当前请求url 就觉得很奇怪
讲道理只要完全模拟整个报文就应该可以返回正确的响应头信息 但是目前请求头与抓包的请求头一致的情况下还是不行 还有建议我去比较原始的报文信息的hhh
我目前采用的替代方案是利用抓包工具复制页面的请求 然后重发 这种方式也不是很稳定 有时候返回正确的目的url,有时候返回当前请求的url....
其他回答(1)
0
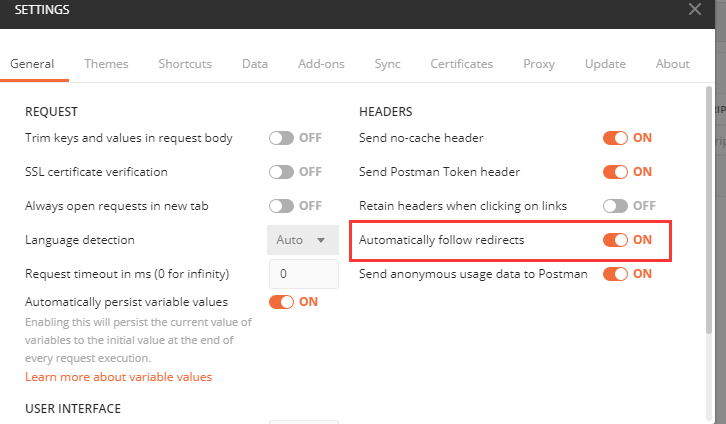
POSTMAN需要设置“自动跟踪重定向”设置 为禁用
收获园豆:30
