






算法-树-权限问题
1

http://www.camelcat.com/2019/921.html
今天跟大家聊一个算是算法思路吧!因为这个,我们团队在公司折腾到凌晨4点。由于不方便直述业务内容,我在这做了概念转换,也便于大家理解领悟吧。
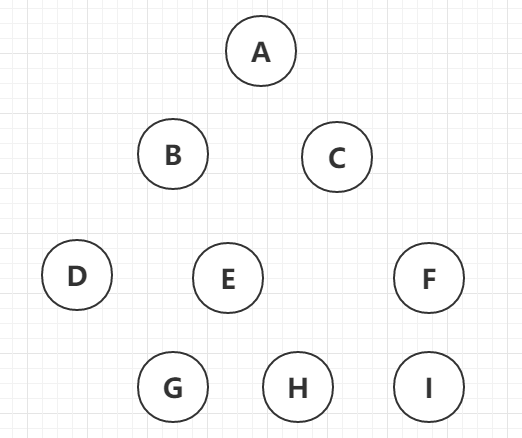
模型很简单,如下图有9个房间,每个房间都有文件,9把钥匙可以开打对应的房间取到对应文件。(如:钥匙A可以打开房间A,取到对应文件a)
上面这个比较好理解,那么我们加深一层模型,加一个单向通道,每个房间都能通往它的上级房间,如下图。我们暂且把这个称之为”房间网络层级图“
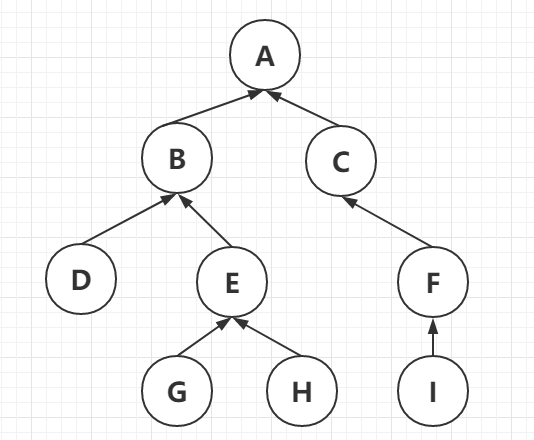
那么,如果你有钥匙B就可以打开房间B,即可以取到文件a和文件b。
好的,已经有了个初步认知了,咱们来个快问快答:
问:你有钥匙D、E、F,请问能取到哪些文件?
答:a、b、c、d、e、f共6个文件。
问:你想取到b、f文件,请问需要拥有哪些钥匙?
答:至少需要拥有两把钥匙,B\D\E\G\H这5把需要持有其中一把,F\I这2把需要持有其中一把即可,所以说两把钥匙的组合就有5*2=10种情况。(满足这10种组合情况下,拥有更多的其他钥匙当然也可以取到文件。)
问:若想取到a文件,请问有需要拥有哪些钥匙?
答:持有任意一把钥匙即可。
好了,有了上面问答的热身之后,终极问题来了
小明拥有X把钥匙,共有N份文件,请设计算法,算出小明能取到哪些文件?
补充一下,
1.一个房间可以有多个文件,如:B房间有b1、b2、b3文件。
2.上图只是示例,实际情况房间的层级多样,但是单向通道规则是不变的哈。
在下目前能想到的算法:
算法一:【通过钥匙来匹配文件】
1.循环每把钥匙,把每把钥匙能通往的房间并集得出集合List。(向上搜索,找某点的所有父级)
2.根据所有文件所在的房间与集合List做交集,得出哪些文件有权限查看。
算法二:【通过文件来匹配钥匙】
1.循环每个文件,把可以取到这个文件的钥匙合并得出一个字典集合Dic,文件所在房间相同的无需重复计算。(向下搜索,找某点的所有子集)
(字典的key:文件b1,字典value:钥匙B、D、E、G、H)
2.循环字典Dic,将字典value与钥匙集合进行交集,存在交集的即为有权限查看的文件,最后得出哪些文件有权限查看。
这两种功能上都是可行的,But性能上会因为数据差异而相差甚远。
单单使用算法一、或者算法二都绝不为最佳方案,但我目前还未想明白该如何设计此最优算法,求大神们指教!
小分析下算法一、二的局限性吧!
我能想到的一些局限性:
1.【钥匙数远大于文件数时,算法一不可取】
假设你拥有100000把钥匙,但是文件数量才十几个甚至几个,还用算法一吗?
2.【房间网络层级图规模庞大时,若有文件在房间A,算法二有点慌】
假设有个文件所在房间就是顶点房间A,那么算法二就得遍历搜索他的所有子集,相当于遍历了整颗树,若这个房间网络层级图非常庞大,那这种算法也是可取吗?...
(或者说是房间B,也几乎要遍历整个房间网络层级图)
我认为应当考虑如下因素,但不知道如何进行平衡:
1.房间网络层级图的规模
2.拥有的钥匙数目
3.文件数量
如今终日陷入沉思中无法自拔,如果有好心人看到帮忙传播一下,若有大神解惑,必有重谢!”感恩的心,感谢有你~~“


所有回答(2)
0
写得不是很清楚。
上一个思路:用空间办法解决时间问题。
做一个能快速查询的线性存储。
谢谢你的回答
0
我大致了解 楼主的需求 和 两种解法的思路。个人认为,算法一可行(复杂度= O(房间的数量+文件的数量)),算法二不可行(复杂度过高),没必要这么做。
核心需求:小明拥有X把钥匙,共有N份文件,请设计算法,算出小明能取到哪些文件?
因为楼主并没有指出 输入的数据是什么?
所以我假设 楼主的输入数据是 : 整颗树的层级关系 和 各个房间拥有的文件编号,总钥匙数量=总房间数量(也就是一把钥匙开一个房间,一个房间只有一把钥匙)。
比如输入
struct Room
{
int [] files; //拥有的文件列表编号
int parentRoomId;//这个房间的 父房间编号
int id;//当前房间的编号 id
};为什么我说方式一合理?
因为方式一的算法就是 线性的,复杂度 = O(钥匙的数量 + 文件的数量);
假如楼主的问题是 说 钥匙数量太多,请问这个钥匙数量会多到什么程度,会超过100w吗?如果不会的话,
算法一程序执行速度应该不是问题。
实现过程需要一个 标记数组 和一个队列q 。
假设有allKeys 个房间,也就是有allKeys 把钥匙。
标记数组 bool checked[i] ; 表示 第 i 个房间我们已经遍历过了。
q用来存放我们即将遍历的房间。
伪代码:
#include<stdio.h>
#include<queue>
using namespace std;
struct Room
{
int [] files; //拥有的文件列表编号
int parentRoomId;//这个房间的 父房间编号
int id;//房间id
};
int main(){
//输入,我们得到了roomList数组 , 一开始我们拥有的钥匙
Room roomList[128]; // 树的层级关系
int [] begin_we_have_keys; //一开始我们拥有的钥匙
//输出:
bool hasFile[] ; // hasFile[i] = true,表示编号为i的这个文件我们拿到了。
//核心代码
queue<Room> q; //一个栈
bool [] checked; //标记数组
for(int i = 0; i< begin_we_have_keys.length ; i++) {
if(!checked[i]){
q.add(roomList[i]);//即将访问的房间
checked[i] = true; //表示已经遍历过了这个房间
}
}
while(q.size()>0){
Room top = q.pop();
for(int i : top.files){ //拿到这个房间的所有书
hasFile[i] = true;
}
if(!checked[top.parentRoomId]){ //检查父房间是不是访问过,没有的话,继续访问。
q.push(roomList[top.parentRoomId]);
}
}
//遍历输出我们拿到的文件编号
for(int i=0; i< allFiles;i++){
if(hasFile[i]==true){
printf("%4d ",i);
}
}
}通过代码可以看到,复杂度=O(房间数 + 文件数) , 其实这就是 【拓扑排序】 的过程。
我个人认为拓扑排序就可以解决这个问题,希望对你有帮助,欢迎一起讨论,谢谢。
感谢你的回答~!看懂了你的算法,good
就是我这遇到个奇葩情景,这个房间网络层级很大,大约有8千多个房间,然后拥有6千多个钥匙。
但是就5个文件,所以才会想到是不是有更加容易的,从文件出发角度。。
@camelcat:
楼主,我能理解你的想法,就是对于 文件很少,但是房间数很多的情况,有没有更优的解决方案。
输入是:①树的层级关系;②文件和对应的房间位置List[name:'fileA';where:'房间B'];③我拥有的钥匙数量。
我的想法是这样的:
【比如 只有两份资料,资料所在的房间位置分别在A和B,我们拥有的钥匙(比如说拥有的是房间C和D的钥匙) ,虽然总资料数量很少,但是【资料所在房间】 和【我们能打开的房间】的相对位置我们是不清楚的,所以我们没有选择,只能选择从叶子节点逐层遍历,直到找到这两个文件所在的位置,就如算法二您说的,如果刚好这2份文件都在最深的某个根节点,那么我们无异于要遍历整棵树,而且其中还涉及到交集的处理时间,其实是得不偿失的。
一句话概括:根据你的输入,资料少这一点是不能为我们解题提供价值的,所以我还是会选择算法一,因为他是线性的,是比较稳定的。】
tip:算法一还可以有小小的优化(如果我们总的资料数也是已知的,那么当我获得的资料 已经 达到了 总资料数,即可以结束循环),可以灵活一点处理。
比如
...........
int allFileNums; //tip:假如已知所有资料的数量
int hasFileNum = 0; //tip:当前我拥有的资料数目
while(q.size()>0 && hasFileNum<all){ //tip : 已获得的资料书=总资料数,结束循环
Room top = q.pop();
for(int i : top.files){ //tip:拿到这个房间的所有书
hasFile[i] = true;
hasFileNum++; //tip:用有的加1
}
if(!checked[top.parentRoomId]){
q.push(roomList[top.parentRoomId]);
}
}
..................