






hql 运行udf报错
0

请教一个hive udf 的问题,具体情况如下:
hive版本3.1.2
spark版本 spark-3.0.0-bin-without-hadoop
现在创建了个udf函数,具体如下:
public class GetLocation extends GenericUDF {
private final static String path = "https://restapi.amap.com/v3/geocode/geo" +
"?address=%s" +
"&output=json" +
"&key=*";
private String getDistance(String source) {
String url = String.format(path, source);
String s = HttpUtil.doGet(url);
JSONObject object = (JSONObject) JSON.parse(s);
Integer status = object.getInteger("status");
String location = "";
if (status == 1) {
JSONArray array = object.getJSONArray("geocodes");
if (array.size() > 0) {
JSONObject o = (JSONObject) array.get(0);
location = o.getString("location");
}
}
return location;
}
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
// 判断传入的参数个数
if(objectInspectors.length != 1){
throw new UDFArgumentLengthException("Input Args Length Error !!!");
}
// 判断传入参数的类型
if (!objectInspectors[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)
|| !PrimitiveObjectInspector.PrimitiveCategory.STRING.equals(((PrimitiveObjectInspector)objectInspectors[0]).getPrimitiveCategory())){
throw new UDFArgumentException("函数第一个参数不为STRING类型"); // 当自定义UDF参数与预期不符时,抛出异常
}
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
String source = deferredObjects[0].get().toString();
return getDistance(source);
}
@Override
public String getDisplayString(String[] strings) {
return strings.toString();
}
}
函数命名为:get_dis_test
通过测试:get_dis_test('金砖路5.5智造园3栋601,217省道西100米,东艳路48号天元物流园5号库126号', '114.172726,30.585103')
能获取正确的值
但是将函数放入hql中后,就会报错:
select
get_dis_test(a.address_list, a.source)
from (
SELECT
nvl(b.address_list, '湖南省长沙市望城区黄金园街道金山路金桥国际未来城') address_list,
concat(nvl(a.user_longitude, 0), ',', nvl(a.user_latitude, 0)) source
from dwd_tbl_dhk_at_attendance_record a
left join dwd_tbl_dhk_group b on a.group_id = b.group_id
where location_result = 'Outside'
and substr(work_date, 0, 10) = '2022-08-23'
and a.del_flag = 1 and b.del_flag = 1
limit 2
) a;
错误信息如下:
2022-09-06 09:37:38,639 ERROR [IPC Server handler 14 on default port 39576] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Task: attempt_1659664613549_12963_r_000000_3 - exited : java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:113)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:79)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:137)
at org.apache.hadoop.mapred.ReduceTask.runOldReducer(ReduceTask.java:411)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:393)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:110)
... 9 more
Caused by: java.lang.RuntimeException: Failed to load plan: hdfs://bigdata1:8020/tmp/hive/root/8b5b89cb-800a-4971-b9ea-3d567e434fd0/hive_2022-09-06_09-36-56_643_1233183658080103048-105/-mr-10010/045e7eb0-da43-4908-b682-a7723addaa90/reduce.xml
at org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:502)
at org.apache.hadoop.hive.ql.exec.Utilities.getReduceWork(Utilities.java:346)
at org.apache.hadoop.hive.ql.exec.mr.ExecReducer.configure(ExecReducer.java:110)
... 14 more
Caused by: org.apache.hive.com.esotericsoftware.kryo.KryoException: Unable to find class: com.yysz.udf.OutSideDistance
Serialization trace:
genericUDF (org.apache.hadoop.hive.ql.plan.ExprNodeGenericFuncDesc)
colExprMap (org.apache.hadoop.hive.ql.plan.SelectDesc)
conf (org.apache.hadoop.hive.ql.exec.SelectOperator)
childOperators (org.apache.hadoop.hive.ql.exec.LimitOperator)
childOperators (org.apache.hadoop.hive.ql.exec.SelectOperator)
reducer (org.apache.hadoop.hive.ql.plan.ReduceWork)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:156)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readClass(DefaultClassResolver.java:133)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClass(Kryo.java:670)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClass(SerializationUtilities.java:185)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:118)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:161)
at org.apache.hive.com.esotericsoftware.kryo.serializers.MapSerializer.read(MapSerializer.java:39)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readClassAndObject(Kryo.java:790)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readClassAndObject(SerializationUtilities.java:180)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:134)
at org.apache.hive.com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:40)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:708)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:218)
at org.apache.hive.com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:125)
at org.apache.hive.com.esotericsoftware.kryo.serializers.FieldSerializer.read(FieldSerializer.java:551)
at org.apache.hive.com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:686)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities$KryoWithHooks.readObject(SerializationUtilities.java:210)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializeObjectByKryo(SerializationUtilities.java:729)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:613)
at org.apache.hadoop.hive.ql.exec.SerializationUtilities.deserializePlan(SerializationUtilities.java:590)
at org.apache.hadoop.hive.ql.exec.Utilities.getBaseWork(Utilities.java:474)
... 16 more
Caused by: java.lang.ClassNotFoundException: com.yysz.udf.OutSideDistance
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hive.com.esotericsoftware.kryo.util.DefaultClassResolver.readName(DefaultClassResolver.java:154)
... 59 more
有大神碰到过类似的问题吗,求解答
通过:select get_dis_test('金砖路5.5智造园3栋601,217省道西100米,东艳路48号天元物流园5号库126号', '114.172726,30.585103') 运行正常
而
select
get_dis_test(a.address_list, a.source)
from (
SELECT
nvl(b.address_list, '湖南省长沙市望城区黄金园街道金山路金桥国际未来城') address_list,
concat(nvl(a.user_longitude, 0), ',', nvl(a.user_latitude, 0)) source
from dwd_tbl_dhk_at_attendance_record a
left join dwd_tbl_dhk_group b on a.group_id = b.group_id
where location_result = 'Outside'
and substr(work_date, 0, 10) = '2022-08-23'
and a.del_flag = 1 and b.del_flag = 1
limit 2
) a;
运行报错

最佳答案
0
看报错中有提到找不到类 :Caused by: org.apache.hive.com.esotericsoftware.kryo.KryoException: Unable to find class: com.yysz.udf.OutSideDistance
1.java运行环境的jdk版本比class文件的编译版本低了导致
2.class文件的访问权限或者所在目录的访问权限有问题,导致java无法读这个文件
3.jar包有错误,查看jar是否有漏或者重新导入jar包
如解决望采纳!
收获园豆:50
您好,jdk版本都是1.8的。权限也没有问题。结尾处也有描述,当参数写死时,运行是正常,所以函数是能正常读取到的,也可以说明jar包没有问题,
否则
select get_dis_test('金砖路5.5智造园3栋601,217省道西100米,东艳路48号天元物流园5号库126号', '114.172726,30.585103')
也无法正常执行。
目前我做了相应修改。改为一个参数,再到udf中将参数拆为2个,在hive 控制台能正常执行了。代码如下:
但是这只是查询,我需要将结果存储。
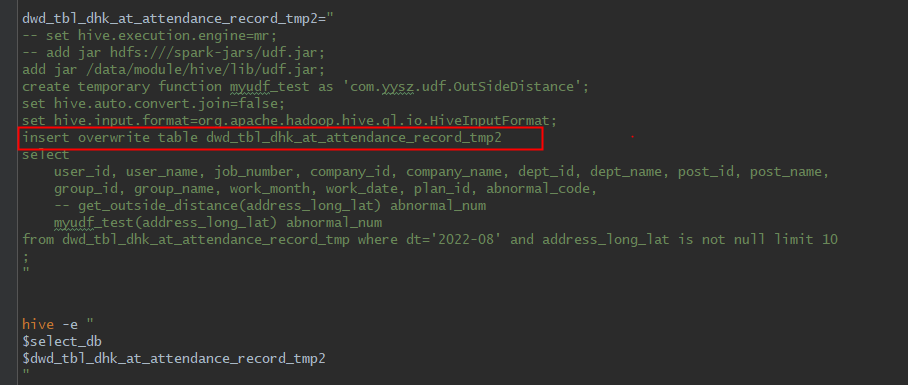
如上图增加 insert overwrite table 错误信息如下(不会进入udf类):
2022-09-07T19:50:39,527 INFO [5528688e-b812-4cac-8da1-ef7c6beb2309 main] status.SparkJobMonitor: Spark job[0] status = RUNNING
2022-09-07T19:50:39,527 INFO [5528688e-b812-4cac-8da1-ef7c6beb2309 main] status.SparkJobMonitor: Job Progress Format
CurrentTime StageId_StageAttemptId: SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount
2022-09-07T19:50:39,540 INFO [5528688e-b812-4cac-8da1-ef7c6beb2309 main] status.SparkJobMonitor: 2022-09-07 19:50:39,528 Stage-0_0: 0/2 Stage-1_0: 0/1 Stage-2_0: 0/1
2022-09-07T19:50:42,581 INFO [5528688e-b812-4cac-8da1-ef7c6beb2309 main] status.SparkJobMonitor: 2022-09-07 19:50:42,580 Stage-0_0: 0/2 Stage-1_0: 0/1 Stage-2_0: 0/1
2022-09-07T19:50:43,594 INFO [5528688e-b812-4cac-8da1-ef7c6beb2309 main] status.SparkJobMonitor: 2022-09-07 19:50:43,593 Stage-0_0: 0(+1,-4)/2 Stage-1_0: 0/1 Stage-2_0: 0/1
2022-09-07T19:50:43,810 INFO [RPC-Handler-2] client.SparkClientImpl: Received result for 5ddce88b-e7cb-492e-8cbd-fe1f1d6d5e0e
2022-09-07T19:50:44,595 ERROR [5528688e-b812-4cac-8da1-ef7c6beb2309 main] status.SparkJobMonitor: Job failed with org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 5, bigdata3, executor 2): UnknownReason
java.util.concurrent.ExecutionException: Exception thrown by job
at org.apache.spark.JavaFutureActionWrapper.getImpl(FutureAction.scala:282)
at org.apache.spark.JavaFutureActionWrapper.get(FutureAction.scala:287)
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:382)
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:343)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 1 in stage 0.0 failed 4 times, most recent failure: Lost task 1.3 in stage 0.0 (TID 5, bigdata3, executor 2): UnknownReason
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2023)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:1972)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:1971)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1971)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:950)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:950)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:950)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2203)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2152)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2141)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
2022-09-07T19:50:44,679 INFO [5528688e-b812-4cac-8da1-ef7c6beb2309 main] reexec.ReOptimizePlugin: ReOptimization: retryPossible: false
@天边ㄨ流星: 您好,https://blog.csdn.net/qq_44463295/article/details/112548312 第二种可能性会大一点
@Biuget-Golang: 感谢回复。现在还没有找到根本问题。我现在先用java去实现了,有时间再回头看这个。感谢。
