






关于MySQL随机数使用ceil取整后左关联其他表出问题这件事
0
[已解决问题]
解决于 2023-07-28 08:20

如题
select a.*,b.help_topic_id from (
(select * from (SELECT *,ceil(RAND()*1000)%4+1 xx FROM mysql.help_topic)tmp)a
left join
mysql.help_topic b on a.xx=b.help_topic_id
)
执行如上语句之后,关联出来的结果集数据条数总是少于
select * from (SELECT *,ceil(RAND()*1000)%4+1 xx FROM mysql.help_topic)tmp
的数据条数,并且关联条件没有成功生效
已知是去掉ceil之后数据条数会恢复正常,但是这样就无法关联了。
(试过substr,不行。而且小的目前也只想知道为撒子这么执行会有问题死个明白。小的菜逼,大佬们轻喷)
执行结果如图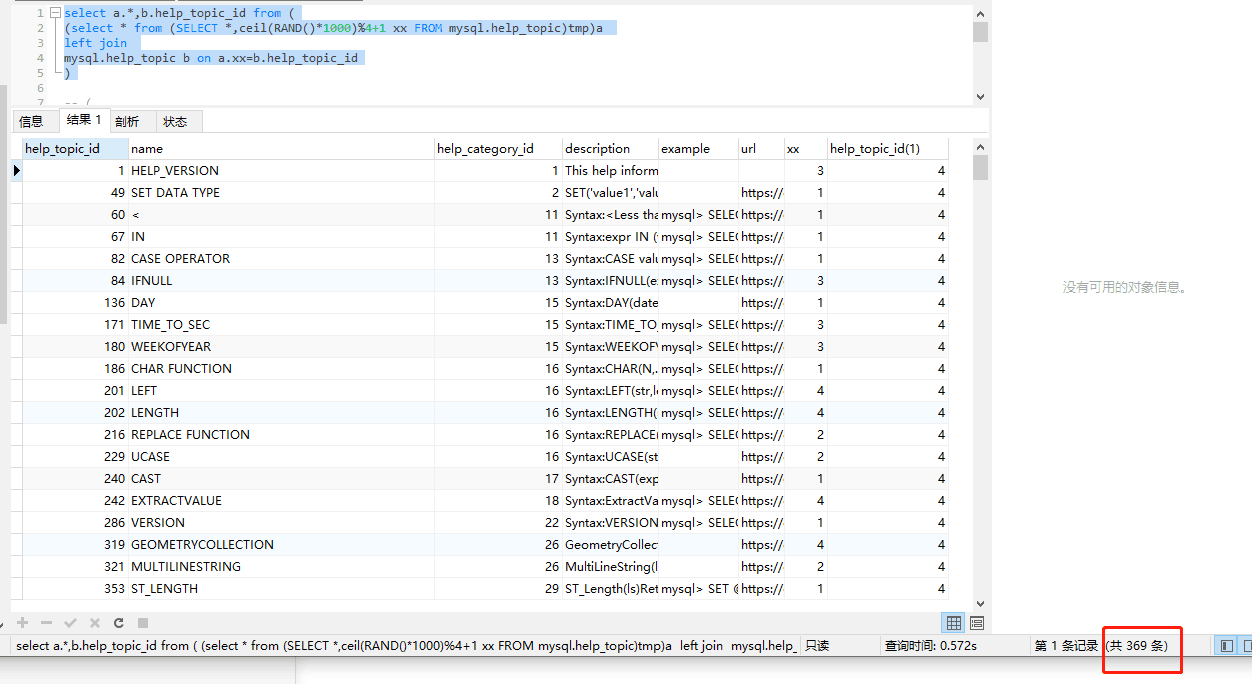
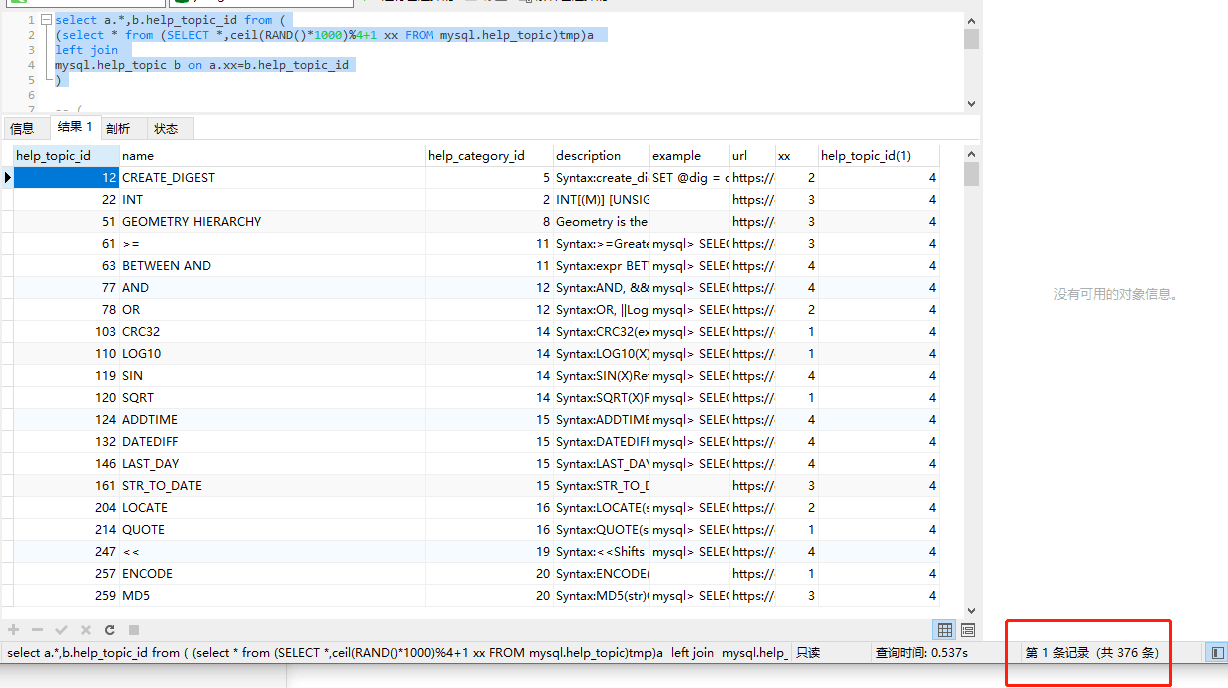
主表总数如图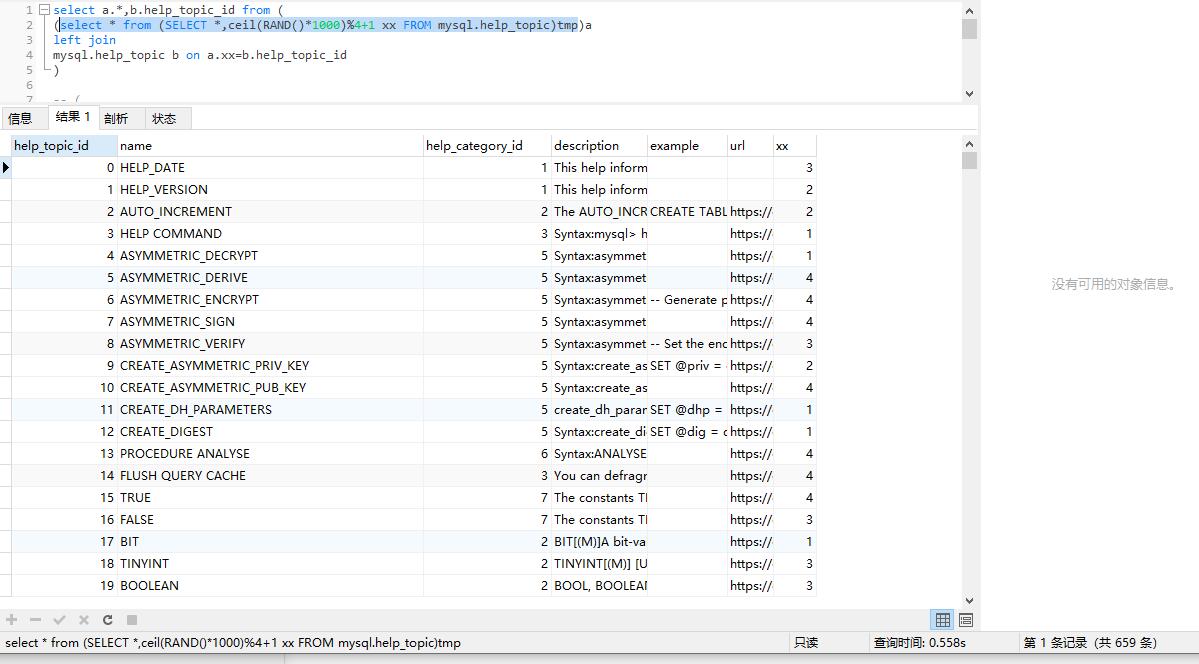


最佳答案
0
首先,解释一下为什么在执行带有 ceil(RAND()*1000)%4+1 的子查询时,关联结果的数据条数会少于原始子查询的数据条数。
-
子查询
SELECT *, ceil(RAND()*1000)%4+1 xx FROM mysql.help_topic:
这个子查询会为mysql.help_topic表的每一行生成一个新的xx列,其中xx的值是通过RAND()函数生成的一个随机小数乘以1000,并向上取整,然后再对4取余并加1得到的结果。这样,xx列的值将是1、2、3或4中的一个。 -
主查询:
在主查询中,我们将上面的子查询作为子查询a并给其取了一个别名。然后我们与mysql.help_topic表进行左连接,连接条件是a.xx = b.help_topic_id。
问题出在这里:
由于 xx 是一个随机生成的列,并且每次查询时都会生成新的随机值,所以在主查询中与 mysql.help_topic 表进行左连接时,a.xx 列的值是不固定的,而且在不同的连接尝试中可能不同。
这意味着,连接条件 a.xx = b.help_topic_id 可能在某些连接尝试中找不到匹配,导致连接结果中某些记录被过滤掉,从而使关联结果的数据条数少于原始子查询的数据条数。
为了解决这个问题,可以通过将 ceil(RAND()*1000)%4+1 的结果存储为一个固定值,然后再进行关联。这样就可以确保连接条件在不同连接尝试中保持一致。
以下是修改后的查询语句:
SELECT a.*, b.help_topic_id
FROM (
SELECT *, (SELECT ceil(RAND()*1000)%4+1) xx FROM mysql.help_topic
) a
LEFT JOIN mysql.help_topic b ON a.xx = b.help_topic_id;
在这个修改后的查询中,将 ceil(RAND()*1000)%4+1 的子查询移动到了 SELECT 子句中,通过 (SELECT ceil(RAND()*1000)%4+1) xx 这样的方式将 xx 列的值设置为一个固定的随机值,并在主查询中使用它进行关联,从而避免了连接条件不一致的问题。
奖励园豆:5
谢谢大佬
其他回答(2)
0
这个问题可能是因为 RAND() 函数在查询过程中多次调用导致的。在 MySQL 中,当一个查询中多次使用 RAND() 函数时,每次调用返回的随机数是不一样的。而且,由于 RAND() 函数的计算是根据查询的行数触发的,因此每个子查询的行数可能不同,导致左连接的结果条数和关联条件不匹配。
为了解决这个问题,你可以将 RAND() 函数的结果先存储为一个变量,然后在多个子查询中使用该变量。这样,对于每个子查询,都会使用相同的随机数,从而保持结果的一致性。
以下是修改后的代码示例:
SET @rand_num = ceil(RAND()*1000)%4+1;
SELECT a.*, b.help_topic_id
FROM (
SELECT *
FROM (
SELECT *, @rand_num as xx
FROM mysql.help_topic
) tmp
) a
LEFT JOIN mysql.help_topic b ON a.xx = b.help_topic_id;
在上面的示例中,我们首先将 RAND() 函数的结果存储在变量 @rand_num 中。然后,在子查询中使用该变量,确保每个子查询都使用相同的随机数。
但是,大佬,现在需要的是每一行都有一个1-4的随机数,如果SET @rand_num这样的话随机数固定了,每一行就只能用rand_num了那这个随机数就么得意义了。
另外您提到的由于 RAND() 函数的计算是根据查询的行数触发的,因此每个子查询的行数可能不同这句能展开说说吗,是指 SELECT *,ceil(RAND()*1000)%4+1 xx FROM mysql.help_topic 这个子查询每次执行返回的结果集行数都不一致吗?
@rfmp: 在 MySQL 中,RAND() 函数的计算是基于查询的行数触发的。这意味着,如果在子查询中使用 RAND() 函数生成随机数,并且子查询的行数会随着每次执行而变化,那么每次执行子查询返回的结果集的行数可能不同。
在你的代码示例中,子查询 SELECT *, ceil(RAND()*1000)%4+1 as xx FROM mysql.help_topic 返回的结果集行数可能会有不同的行数。每次执行子查询时,RAND() 函数会生成一个随机小数,然后根据行数的触发条件对结果进行计算。
这种不确定性是由于 RAND() 函数在计算时依赖于MySQL的查询执行逻辑。因此,无法保证每次执行子查询都会产生相同的行数。如果你希望子查询返回的结果集行数保持一致,可以在子查询之前先将查询结果存储到一个临时表中,然后使用该临时表进行后续的操作。
@rfmp: 你可以使用 UUID() 函数来替换RAND()函数:UUID() 函数可以生成一个全局唯一的标识符,可以将其用作随机数。但需要注意的是,生成的是一个字符串格式的唯一标识符,而不是数字类型的随机数。
示例代码:
SELECT a.*, b.help_topic_id, UUID() as random_num
FROM mysql.help_topic a
LEFT JOIN mysql.help_topic b ON random_num = b.help_topic_id;
@lanedm: 好的,谢谢大佬
0
首先,让我们来理解一下为什么在使用ceil(RAND()*1000)%4+1表达式后,关联出来的结果集数据条数总是少于SELECT , ceil(RAND()1000)%4+1 xx FROM mysql.help_topic的数据条数。
问题出在LEFT JOIN和ON条件上。当你使用ceil(RAND()*1000)%4+1来生成随机数,并在关联时使用这个随机数作为关联条件,会导致LEFT JOIN的匹配问题。
LEFT JOIN是左连接操作,它会返回左表中所有的记录,不管右表中是否有匹配的记录。但是,当你使用ceil(RAND()*1000)%4+1作为关联条件时,它实际上会在每次查询时计算一个新的随机数,导致左表中的每一行都无法与右表中的行匹配,因为右表中并没有相应的随机数。
为了解决这个问题,你需要确保在关联时使用的随机数是一致的,而不是每次都重新计算。可以通过使用子查询或临时表的方式来实现。
以下是使用子查询的示例:
sql
Copy code
SELECT a., b.help_topic_id
FROM (
SELECT , ceil(RAND()1000)%4+1 xx
FROM mysql.help_topic
) AS a
LEFT JOIN mysql.help_topic AS b ON a.xx = b.help_topic_id;
这样,通过将ceil(RAND()1000)%4+1计算的结果放入子查询中,保证了关联条件使用的随机数在查询期间是一致的,这样就可以得到正确的关联结果。
使用临时表的示例:
sql
Copy code
CREATE TEMPORARY TABLE tmp_help_topic AS
SELECT , ceil(RAND()1000)%4+1 xx FROM mysql.help_topic;
SELECT a.*, b.help_topic_id
FROM tmp_help_topic AS a
LEFT JOIN mysql.help_topic AS b ON a.xx = b.help_topic_id;
这里我们先将生成的随机数结果存储在临时表tmp_help_topic中,然后再进行关联查询,同样可以得到正确的关联结果。
请记住,随机数生成只需要计算一次,并将结果存储在临时表或子查询中,以保证在关联时使用的随机数是一致的。这样就能够正确地进行关联查询。
