






sql server中not in,in与not exists,exists有什么不同
1



所有回答(4)
0
IN 和 NOT IN后面的数据格式
IN (ID1,ID2,...)
select 也可以啊
0
上次回了你的贴子,这次继续
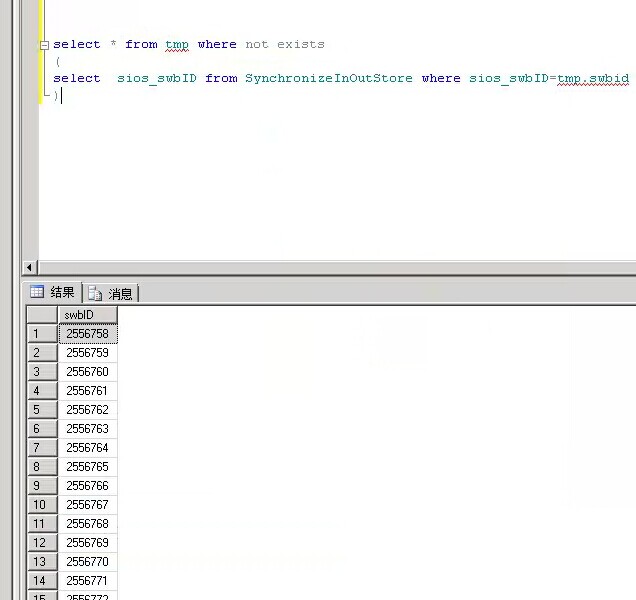
不存在是指 把后面存在的情况给筛选掉,即排除temp表里面有swpid出现的数据,按你的结果集 在前面 not in 是应该有数据的,你这种却没有,依据你这个 temp表里有不识别的情况,应该是你新建的表,建议你检查下两个表的字段类型,贴下图
temp表示新建的,但不是临时表,实际上temp就一列,int类型,没有null值,
@付鹏DragonDeal(龙易): in 没有,not in 没有,明显就空的啊...,但是你后面不存在却有,如果可以的话加我QQ,我远程看下
@风醉: 谢谢,客户那里的,就是因为这个问题导致了这两周客户一直反映很多货单不正常,我后来使用exists查询了一下,190多个单据都有问题,我一次性用exists全部手动解决了,程序中也换成了exists,以后估计不会出现问题了。
@付鹏DragonDeal(龙易): 一般这种离奇事件,其实可能就是一个细节问题,能解决问题就好
1
--如果我们要比较两个字段的话我们可以使用+号前提是“字段1,字段2”为字符型,否则需要转换
SELECT * FROM #tempTable1 tt WHERE argument1+argument2 IN (SELECT argument1+#tempTable2.argument2
FROM #tempTable2 )
--如果我们要比较两个字段的话我们可以使用and号但是IN他只能认识一个表达式
--FROM #tempTable1 tt先执行这段然后作为where的参数然后传入子查询里面
--in()后面的子查询 是返回结果集的,换句话说执行次序和exists()不一样.子查询先产生结果集
--然后主查询再去结果集里去找符合要求的字段列表去.符合要求的输出,反之则不输出.
SELECT * FROM #tempTable1 tt WHERE argument1 IN (SELECT argument1
FROM #tempTable2 WHERE tt.argument2=#tempTable2.argument2)
--exists()后面的子查询被称做相关子查询 他是不返回列表的值的.只是返回一个ture或false的结果(这也是为什么子查询里是"select 1"的原
--换成"select 6"完全一样,当然也可以select字段,但是明显效率低些)子表大的时候选着EXISTS
SELECT * FROM #tempTable1 tt WHERE EXISTS (SELECT 1
FROM #tempTable2 WHERE tt.argument1=#tempTable2.argument1)
--EXISTS的执行流程
--select * from t1 where exists ( select null from t2 where y = x )
--可以理解为:
--for x in ( select * from t1 )
-- loop
-- if ( exists ( select null from t2 where y = x.x )
-- then
-- OUTPUT THE RECORD
--end if
--end loop
--对于in和exists的性能区别:
--如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in,反之如果外层的主查询记录较少,
--子查询中的表大,又有索引时使用exists。
--其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),
--如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,
--所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了
0
not in是选出了不存在的。。如果没有不存在的数据当然就是空的了。。。
