






sql 问题 求解锁 详情请看sql
0
[已解决问题]
解决于 2015-03-17 14:30

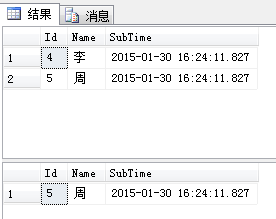
Info表中有五条记录(下图),请看sql:
select * from [Info] where [Id]>3 order by [SubTime] asc select top 1 * from [Info] where [Id]>3 order by [SubTime] asc
为什么 Top 1的结果不是Id为4的而是Id为5的?求知道的园友解释一下,在线等!!!
附上建表和数据的sql:


USE [xiaocainiao] GO /****** Object: Table [dbo].[Info] Script Date: 2015/1/30 16:41:25 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Info]( [Id] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](50) NOT NULL, [SubTime] [datetime] NOT NULL, CONSTRAINT [PK_Info] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[Info] ADD CONSTRAINT [DF_Info_SubTime] DEFAULT (getdate()) FOR [SubTime] GO
图:



最佳答案
0
此问题没什么纠结的,很正常的,其实结果的不正常的原因在于使用不当,本身TOP的使用时配合order by配合使用的,并且保证在order by有效的情况下才能正常的TOP N列。
而楼主的时间列都一样,所以这里的TOP N理论应为随机值,但是再深入一点你会发现这块数据并非随机,底层是根据数据页中的数据排序进行倒序输出的,这一点目的我感觉就是为了保证性能,因为表中存在聚集索引,所以底层数据为为了保证排序有TOP N是从获取完数据后倒序输出的。
顺便说一下:菠萝兄提到的此查询并非index scan...而是index seek....
奖励园豆:5
有没有这方面的资料提供一下,是因为索引的问题是吗?
@晓菜鸟: 去我博客园看看吧:http://www.cnblogs.com/zhijianliutang/
是index scan啊

@我是大菠萝: 菠萝兄,我这边是seek...版本是Server 2012 sp1...

不过我也在纳闷这里几点:
<1>我这里用索引Seek,查询是*它是怎么获取到其它列的?我才是SQL12里面的新特性...
<2>你的查询条件怎么没有动态参数化?你改系统参数了?
@指尖流淌: 我是08 R2,参数化默认为简单

你执行计划里显示不是clustered index seek么?直接从聚集索引的叶子页就可以获取其他列的value 啊
其他回答(4)
0
告诉我为什么结果应该是 4 ,而不是 5 呢?
我是这样想的,按照[SubTime] 升序排列时,4是在5前面的,然后我去 Top 1,应该是先取到4而不是5,不知道这样想对不对。
@晓菜鸟: 你执行下看看:
select * from [Info] where [Id]>3 order by [SubTime] desc
select top 1 * from [Info] where [Id]>3 order by [SubTime] desc
@Launcher: 执行结果是一样的。您是想说当时间一样时,这个OrderBy无效?
@晓菜鸟: 我没有说无效吧!如果让你来设计排序算法,你遇到排序字段值一样时,你该如何确定它们的顺序呢?
@Launcher: 第一排序字段存在重复值,我会加上第二排序字段。我想的时,虽然时间都是一样的值,但是我直接排序 4 都是在 5 前面的,那我 Top 1 取到的不应该是 4 吗? 他这个跟索引有关系吗?还是跟物理存储有关系?
@晓菜鸟: order by 不指定 asc 时,默认 asc 还是 desc ?
@Launcher: asc啊!
@晓菜鸟: 把创建在 Id 上的主键给删除掉,看下结果。
@Launcher: 大神,主键删除之后执行上面的sql语句,执行结果还是一样的,难道是缓存?求指点
@Launcher: 因为我 select * from [Info] where [Id]>3 order by [SubTime] asc 的查询结果 4 是排在 5 前面的,我再在前面加一个 Top 1 ,我想的是应该取到的是第一个满足条件的啊!难道是因为执行 where 的时候先找到了 5 ,又或者是什么其他的因素影响了,就是看能不能弄清楚他。
@晓菜鸟: 然后把 Name 设置为主键
@Launcher: 大神,我把Name设置成主键之后执行上面的Sql语句,结果还是一样的,这几天我也看了一些资料,小弟还是没有明白您想给我引导的意思。
@晓菜鸟: 这样吧,啥都不要改,还是按照你原先的表结构和数据,你执行下面的语句,对比下结果:
1:
select * from [Info] where [Id]>3 order by [SubTime] asc
select top 2 * from [Info] where [Id]>3 order by [SubTime] asc
2:
select * from [Info] where [Id] < 5 order by [SubTime] asc
select top 1 * from [Info] where [Id] < 5 order by [SubTime] asc
3:
select * from [Info] where [Id] < 5
select top 1 * from [Info] where [Id] < 5
@Launcher: 不要排序的Sql语句得到的是我感觉正常的结果,这是因为系统默认按照主键索引进行排序对吧!
@晓菜鸟: select * from [Info] where [Id]>3 order by [SubTime] asc
select top 2 * from [Info] where [Id]>3 order by [SubTime] asc
你注意这个结果了吗?
从逻辑上推断,这两条语句选出来的结果应该是一样的,但是你看输出窗口,它们的输出顺序恰好是反的。
@Launcher: 看到了,那么这种现象怎么解释呢?
@晓菜鸟: 你写个程序用二叉树排序算法试试。
@Launcher: 大神,整这么高端。
@晓菜鸟: 要不你去找本 Microsoft Sql server 2008 Internals 读读。
@Launcher: 这个可以有。赞!
0
感觉4看起来比较优雅? 还是你的幸运数字是4?
我是这样想的,按照[SubTime] 升序排列时,4是在5前面的,然后我去 Top 1,应该是先取到4而不是5,不知道这样想对不对。
大叔,指点一二。
@晓菜鸟: 这个是数据库设计原理了,我水平比较低,很少接触这么高深的话题。
真话是我一般不让自己陷入这种困境里面。
我放弃使用自增ID好多年了,从来不信自增ID能当成排序的依据。
@爱编程的大叔: 额,恕小弟愚昧,我不是用的时间排序吗?跟ID自增有关系?
@晓菜鸟: 既然你用的时间排序,为什么你会认为4应该在5前面呢?
@爱编程的大叔: 因为我 select * from [Info] where [Id]>3 order by [SubTime] asc 的查询结果 4 是排在 5 前面的,我再在前面加一个 Top 1 ,我想的是应该取到的是第一个满足条件的啊!
@晓菜鸟: 你想没有用啊。
你完全没有明白我的意思,不要把希望寄托在别人身上,你如果想按照ID排序,
你直接order by subtime asc, id asc 双排序就好了,为什么一定要单排序,然后又指望他按照你的想象来排呢?
@爱编程的大叔: 额,我就是想弄明白一下,他是怎么得出的 5 ,是因为执行 where 的时候先找到了 5 ,又或者是什么其他的因素影响了,就是看能不能弄清楚他。
@晓菜鸟: 先找到了5。而没有TOP 1的可能是另外一个原因,我也不能确定,就不说出来误导你了。
所以我说你要弄清楚这点,就得去看数据库原理了。
@爱编程的大叔: 哦,看来这个问题不是我开始想的那样简单啊,谢谢大叔了,不过要弄清楚数据库原理可不是一天两天的事,只能慢慢来了!谢谢大叔!非常感谢您耐心的指导!:)
0
时间都一样,这order by有意义?
额,没有意义?
0
1、你的subtime上没有索引,即便order by,也是做cluster index scan,这并不一定保证你的顺序和聚集索引顺序一样
2、如果你在subtime上加了索引,由于非聚集索引的叶子节点为聚集键的value,所以查询出来就是4