






lucene.net与盘古分词简单例子,创建索引后,搜索内容,内容出不来
0

这是创建索引代码
private void button4_Click(object sender, EventArgs e)
{
string IndexPath = @"C:\LuceneTset\lucenedir";//注意和磁盘上文件夹的大小写一致,否则报错,将创建的分词内容放在目录下。
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(IndexPath),new NativeFSLockFactory());//指定索引文件(打开索引目录),FS指的就是FileSystem.
bool isUpdate = IndexReader.IndexExists(directory);//IndexReader:对索引进行读取的类。该语句的作用:判断索引库文件夹是否存在以及索引特征文件是否存在
if (isUpdate)
{
//同时只能有一段代码对索引库进行写操作,当使用IndexWriter打开directory时会自动对索引库文件上锁。
//如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁(提示一下:如果我现在正在写着已经加锁了,但是还没有写完,这时候又来一个请求,那么不就解锁了吗?这个问题后面会解决)
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory);
}
}
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);//向索引库中写索引,这时再这里加锁。
for (int i = 1; i <= 7; i++)
{
string txt = File.ReadAllText(@"C:\LuceneTset\" + i + ".txt",System.Text.Encoding.Default);//注意这个地方的编码
writer.DeleteDocuments(new Term("number", i.ToString()));
Document document = new Document();//表示一篇文档
//Field.Store.YES:表示是否存储原值。只有当Field.Store.YES在后面才能用doc.Get("number");取出值来。Field.Index.NOT_ANALYZED:不进行分词保存。
document.Add(new Field("number", i.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));
//Field.Index.ANALYZED:进行分词保存,也就是要进行全文的字段要设置分词 保存(因为要进行模糊查询)
//Lucene.Net.Document.Field.TermVector.WITH_POSITIONS_OFFSETS:不仅保存分词还保存分词的距离
document.Add(new Field("body", txt,Field.Store.YES, Field.Index.NOT_ANALYZED,Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
writer.AddDocument(document);
}
writer.Close();//会自动解锁
directory.Close();//不要忘了Close() 否则索引结果搜不到
}
这是搜索内容代码:
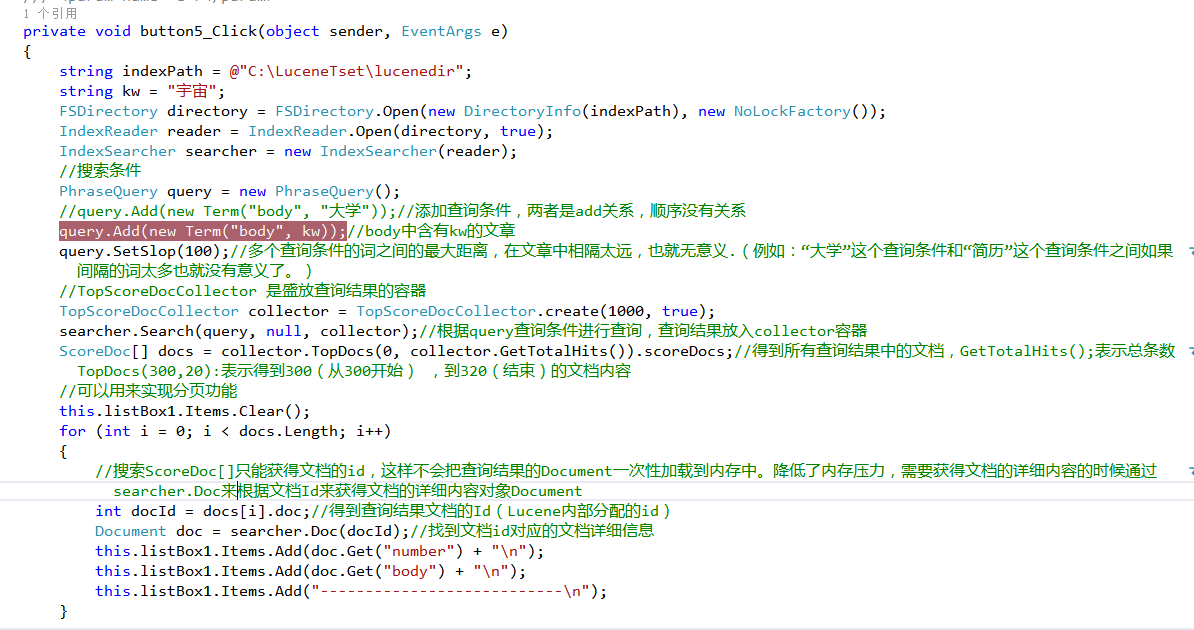


所有回答(2)
0
感觉用的lucene.net与盘古分词效果不怎么好
0
document.Add(new Field("body", txt,Field.Store.YES, Field.Index.NOT_ANALYZED,Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));这里要进行分词保存,所以不应是Field.Index.NOT_ANALYZED,而为Field.Index.ANALYZED。哎,要仔细
