对大数据比较感兴趣,希望经历过的人给一些建议和学习心得。
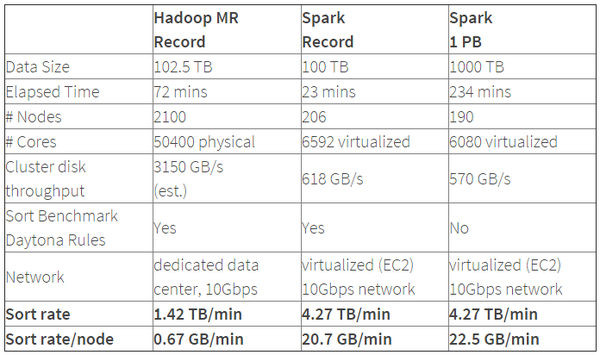
排序100TB的数据(1万亿条数据),Spark只用了Hadoop所用1/10的计算资源,耗时只有Hadoop的1/3。
受教了,虽然之前看了不少这方面的帖子,但是没有给出你这样具体的使用结果。