






在python运行正常,C#在IronPython调用各种报错
0

c#
using System; using System.Collections.Generic; using IronPython.Hosting; using System.IO; public partial class Report_fspcDetail : System.Web.UI.Page { protected void Page_Load(object sender, EventArgs e) { if (!IsPostBack) { initDetail(); } } public void initDetail() { var engine = Python.CreateEngine(); var scope = engine.CreateScope(); //添加路径 ICollection<string> Paths = engine.GetSearchPaths(); Paths.Add("C:\\Python27\\Lib"); Paths.Add("C:\\Python27\\Lib\\json"); Paths.Add("C:\\Python27\\Lib\\site-packages\\bs4"); Paths.Add("C:\\Python27\\Lib\\site-packages"); engine.SetSearchPaths(Paths); var source = engine.CreateScriptSourceFromFile(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "ScrapyCode.py")); source.Execute(scope); //var getDetail = scope.GetVariable<Func<object, object>>("getDetail"); //var json = getDetail("8a81819857699d6601577aa1222f6c70"); var getPlistCode = scope.GetVariable<Func<object,object>> ("getPlistCode"); var json22 = getPlistCode(1); } }
python
# -*- coding:utf-8 -*- import urllib import urllib2 import json from bs4 import BeautifulSoup import sys reload(sys) sys.setdefaultencoding('utf-8') def chineseToUnic(ch): # return ch.decode('utf-8').encode('unicode_escape')[2:] return ch.decode('utf-8').encode('unicode_escape') # 函数 获取页面数据 def getPlistCode(condition): # print(pageNumber) # 1.得到这个网页的 html 代码 # url = 'http://xy.fspc.gov.cn/tentbaseinfoAction!getTentbaseinfoList.do?' # 组装post请求的fromdata数据 postdata = urllib.urlencode({'page': '1', 'pageSize': 10, 'num': '1', 'leftnum': '1', 'creditquery.enterpriseName': u'佛山市三能灯饰工程有限公司', 'creditquery.businessAddress': '', 'creditquery.bussRegNo': '', 'creditquery.tyxyshdm_query': '', 'validateCode': ''}) postdata = postdata.encode('utf-8') # html = urllib.request.urlopen(url,postdata).read() # html = urllib.request.urlopen(url, postdata,10) # print(html.status,html.reason) # r如果状态吗返回非200 则退出抓取程序 # if (html.status != 200): # print("{'status':'error','Msg':'返回代码非200'}") # exit() html = urllib2.urlopen(url, postdata).read() # 2.转换 一种格式,方便查找 soup = BeautifulSoup(html,"html.parser") tables = soup.find_all('table') table = '' for tb in tables: if '以下信息由信用广东网提供' in str(tb): table = tb # print table.encode('gb18030') # if '网页连接超时' in str(tb): # return "网页连接超时" # print(table) # print table.encode('gb18030') if table is not '': rows = table.find_all('tr') if len(rows) != 2: for row in rows: if 'openXyhcDetail' in str(row): temp = str(row).split('\'') if temp is not '': getDetail(temp[3]) # print(temp[3]) else: getDetail('timeOut') # if '网页连接超时' in str(row): # print(BeautifulSoup(row).getText()) def getDetail(qyid): # print qyid if qyid == 'timeOut': #print "网络连接超时" return "网络连接超时" else: url = 'http://xy.fspc.gov.cn/tentbaseinfoAction!getDetail.do?' # 组装post请求的fromdata数据 postdata = urllib.urlencode({'qyid':qyid}) postdata = postdata.encode('utf-8') html = urllib2.urlopen(url, postdata).read() # tables = tables.encode('gb18030') soup = BeautifulSoup(html,"html.parser") # print soup tables = soup.find_all('table') # tables = tables.decode('utf-8').encode('gbk') tabList = [] # 创建一个含有'身份证件号码'的list tempCon = chineseToUnic('身份证件号码') # tempCon = tempCon.encode('utf8').decode('utf8') for tb in tables: # print chineseToUnic(str(tb)) if chineseToUnic(str(tb)).find(tempCon)!= -1: # if tempCon in str(tb): # print type(tb) tabList.append(tb) # print tabList jsonTemp = '' arrJson = [[], [], [], [], [], [], [], [], [], [], []] indexNum = 0 # print(tabList) # print tb tempCon1 = chineseToUnic('姓名').replace('\\','\\\\') tempCon2 =chineseToUnic('身份证件号码').replace('\\','\\\\') tempCon3 = chineseToUnic('职务').replace('\\','\\\\') tempCon4 = chineseToUnic('自然人').replace('\\','\\\\') for tb in tabList: rows = tb.find_all('tr') for row in rows: cells = row.find_all('td') # print chineseToUnic(str(cells)) if chineseToUnic(str(cells)).find(tempCon1)!=-1 or chineseToUnic(str(cells)).find(tempCon2)!=-1 or chineseToUnic(str(cells)).find(tempCon3)!=-1 or chineseToUnic(str(cells)).find(tempCon4)!=-1 : # if tempCon1 in str(cells) or tempCon2 in str(cells) or tempCon3 in str(cells) or tempCon4 in str(cells): # if '姓名' in str(cells) or '身份证件号码' in str(cells) or '职务' in str(cells) or '自然人' in str(cells): jsonTemp += '\'' + cells[0].getText() + '\'' + ":" + '\'' + cells[1].getText() + '\'' + ',' jsonTemp = jsonTemp[:-1] # print(jsonTemp) arrJson[indexNum].append(jsonTemp) indexNum += 1 jsonTemp = '' # print(str(arrJson).replace('\"', '')) # print arrJson jsonResult = json.dumps(arrJson, encoding='UTF-8', ensure_ascii=False) #print jsonResult return jsonResult # print(tabList) #if __name__ == '__main__': # # print('**********************************即将进行抓取**********************************') # # startIndex = input('请输入您要搜索起始页(数字):') # # pageCount = input('请输入您要搜索的结束页(数字):') # # condition = input('请输入您要搜索公司全称:') # getPlistCode(1)
python在pycharm中正常运行
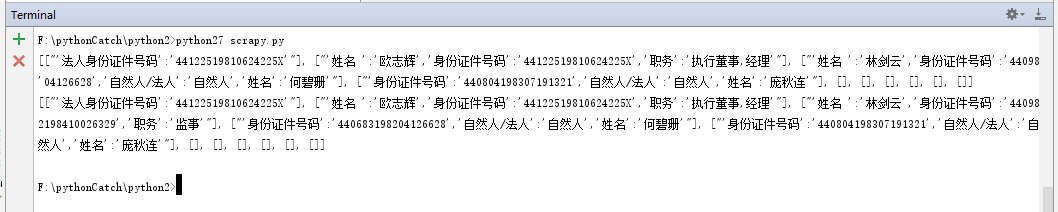
然后再C#利用IronPython 调用时各种报错我都快哭了
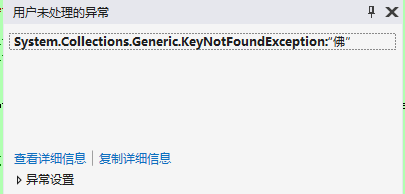
上面代码执行直接报错。我也奇了怪了。
求大神帮我调通,不胜感激


所有回答(3)
0
原生python和ironpython底层的实现应该不太一致可能是导致你出错的原因之一。
另一个,你python的实现的难点无非就是html的解析,但这个在.net下也有第三方组件可以完成,比如Html Agility Pack,直接用类似linq to xml的方式来完成你对节点的查询,后面组装数据这块相比你的代码而言.net在这块会更简单。
如果你实在无法搞定建议你直接用原生的.net来实现。
0
python和ironpython结合完全是坑写不下去了,直接C#了
0
确实,用IronPython太麻烦了,各种跟直接运行的差异,调起来太耗时,从入坑到放弃的典型。。
