







匹配网址的正则表达式
0
[待解决问题]

请问如何用正则表达式获取<a href="http://tiantian.net/2016/01/20/wx-ff-tx.html" target="_blank"><img class="lazy" data-original="//tankr.net/s/custom/Z4Q6.jpg" width="175" height="98" /></a>

所有回答(3)
0
[a-zA-z]+://[^s]* 把这个稍微改一下就好
0
//目标字符串
string source = "http://reg-test-server:8080/download/file1.html# ";
//正则式
string regex = @"(\w+):\/\/([^/:]+)(:\d+)?([^# :]*)";
Regex regUrl = new Regex(regex);
//其他略...
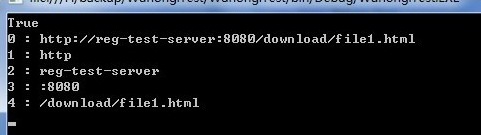
这个可以把全部网址都匹配出来了,不知如何匹配http://tiantian.net/2016/01/20/xxxxxx.html这样的?
@tonyhangzhou: 以http://tiantian.net/2016/01/20/xxxxxx.html这个网址为例,
(\w+):\/\/([^/:]+)(:\d+)?([^# :]{1,12}.?([^# :]*)) 可以自己多看看正则语法、一调就好了
0
都写得太复杂了。
