






sql多表联合查询 左连接的时候只要右表的一条数据
0

如: a ,b 表
a表有个aid 和name,
b表也有个bid,aid ,name
我想a 和b匹配 select * from a left join b on a.aid=b.bid 的时候
只要左边表出现的数据 假如 b表有a表的多条数据的话 我只要b一条数据
总之 就是 假如a有7条数据,那么b也之匹配7条数据出来 多余的不要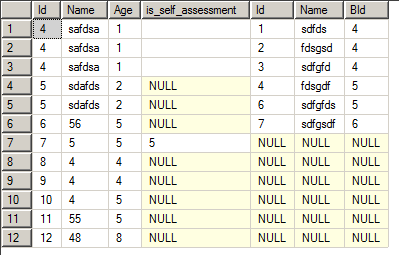


所有回答(3)
0
那就需要一一对应了啊,比如a 有1,2,3 如果b表有 2,2,3,4 那就需要把b表现搞成 2,3,4 就可以组合成
2 2
3 3
就是那个去除重复项 很麻烦的 有很多表连在一起的
@月下诗:
CREATE TABLE #t1 ( id INT NOT NULL, [name] varchar(100) NOT NULL ) CREATE TABLE #t2 ( fid INT NOT NULL, [name] VARCHAR(100) NOT NULL ) CREATE TABLE #t3 ( id INT, [name] VARCHAR(100), fid INT, [fname] VARCHAR(100) ) INSERT INTO #t1 ( id, name ) VALUES ( 1, -- id - int 'a' -- name - varchar(100) ) INSERT INTO #t1 ( id, name ) VALUES ( 2, -- id - int 'b' -- name - varchar(100) ) INSERT INTO #t1 ( id, name ) VALUES ( 3, -- id - int 'c' -- name - varchar(100) ) INSERT INTO #t2 ( fid, name ) VALUES ( 2, -- id - int 'b1' -- name - varchar(100) ) INSERT INTO #t2 ( fid, name ) VALUES ( 2, -- id - int 'b2' -- name - varchar(100) ) INSERT INTO #t2 ( fid, name ) VALUES ( 3, -- id - int 'c1' -- name - varchar(100) ) INSERT INTO #t2 ( fid, name ) VALUES ( 4, -- id - int 'd1' -- name - varchar(100) ) INSERT INTO #t3 SELECT * FROM #t1 LEFT JOIN #t2 ON #t1.id = #t2.fid SELECT * FROM #t3 SELECT * FROM (SELECT t.*, RANK() OVER (PARTITION BY t.id ORDER BY t.fname DESC) AS drank FROM #t3 t) a WHERE drank=1 DROP TABLE #t1 DROP TABLE #t2 DROP TABLE #t3
@chenping2008:这个不行 后面的表有15张
0
同意上楼,如题那就相当于inner join 咯
后面那张表有15张 那个我考虑过的
0
只能是用 inner join 一张张连,除非你设计表的时加上一些冗余字段来减少连接。
